
AI Infrastructure Engineering: Driving JPMorgan’s $2 Billion Return (Part 2)
MLOps and Data Architecture: Scaling 450 Production Models


While headlines tout the transformative power of AI, sustainable value is engineered, not discovered. This deep dive into JPMorgan Chase's technical architecture reveals the operational foundations that turn algorithms into billions in annual return.
A little about my guest today:
John Brewton documents the history and future of operating companies at Operating by John Brewton, where he examines how elite organizations build competitive advantage through operational excellence. A Harvard graduate who began his career as a PhD student in economics at the University of Chicago, John brings both academic rigor and practical experience to his analysis. Having sold his family’s B2B industrial distribution company in 2021 before founding 6A East Partners, a research and advisory firm exploring the fundamental question: What is the future of companies?
His writing spans Operating Economics (dissecting how companies like Amazon and, of course, JPMorgan build optimization engines), Operating History (connecting contemporary strategy to legends like Andy Grove and Alfred Sloan), and the AI Upskilling Playbook (research backed frameworks for career resilience in the AI era). With popular pieces like The AI Skills Crisis Isn’t What You Think and Operating Economics: Building Antifragile Companies, John has built a community of operators, founders, and builders seeking to understand not just what companies do, but how they actually work.
He helps business owners, founders, and investors optimize their operations, translating insights from Fortune 500 transformations into actionable frameworks for companies at any scale. John creates content daily (despite the occasional protests from his beloved wife, Fabiola) and still cringes at his early LinkedIn posts.
Part 1 examined JPMorgan’s financial performance and strategic decisions from 2021-2026: $2 billion in annual AI investment generating $2 billion in returns, 450 production models scaling to 1,000 by year-end, and a workforce transformation that included a 10% reduction in operations staff.
JPMorgan Chase generates $2 billion in annual business value from artificial intelligence by treating model deployment as an industrial engineering challenge. While most organizations prioritize algorithms or talent, JPMorgan focuses on the operational plumbing required to scale.
Success derives from data pipelines processing $10 trillion in daily transactions with zero downtime tolerance, feature stores eliminating training-serving skew across 450 production models, and deployment infrastructure pushing updates to 250,000 employees every eight weeks while maintaining regulatory compliance across 120 jurisdictions.
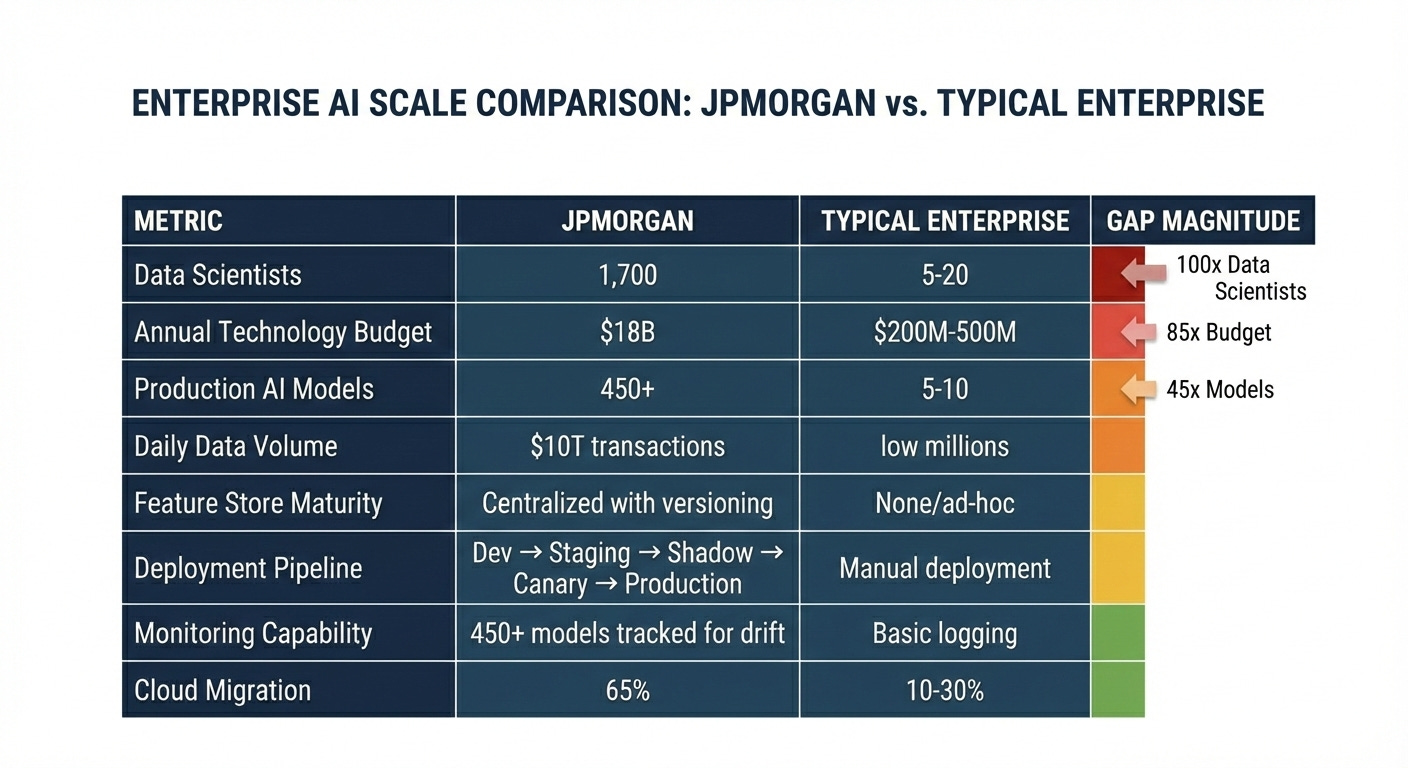
JPMorgan’s AI returns reflect a decade of data engineering that preceded the current AI wave. While competitors scrambled to hire data scientists after ChatGPT’s November 2022 launch, JPMorgan already operated 400+ production use cases spanning fraud detection, credit decisioning, and algorithmic trading. The bank employs 900 data scientists, 600 ML engineers, and a 200-person AI research team. This infrastructure provides a structural advantage that most enterprises cannot replicate, regardless of budget.
This article examines the technical systems generating those returns. These include cloud migration architecture moving petabytes off mainframes, ML lifecycle management serving 1,700 AI specialists, LLM gateway processing millions of employee queries, and real-time fraud detection operating at millisecond latency.
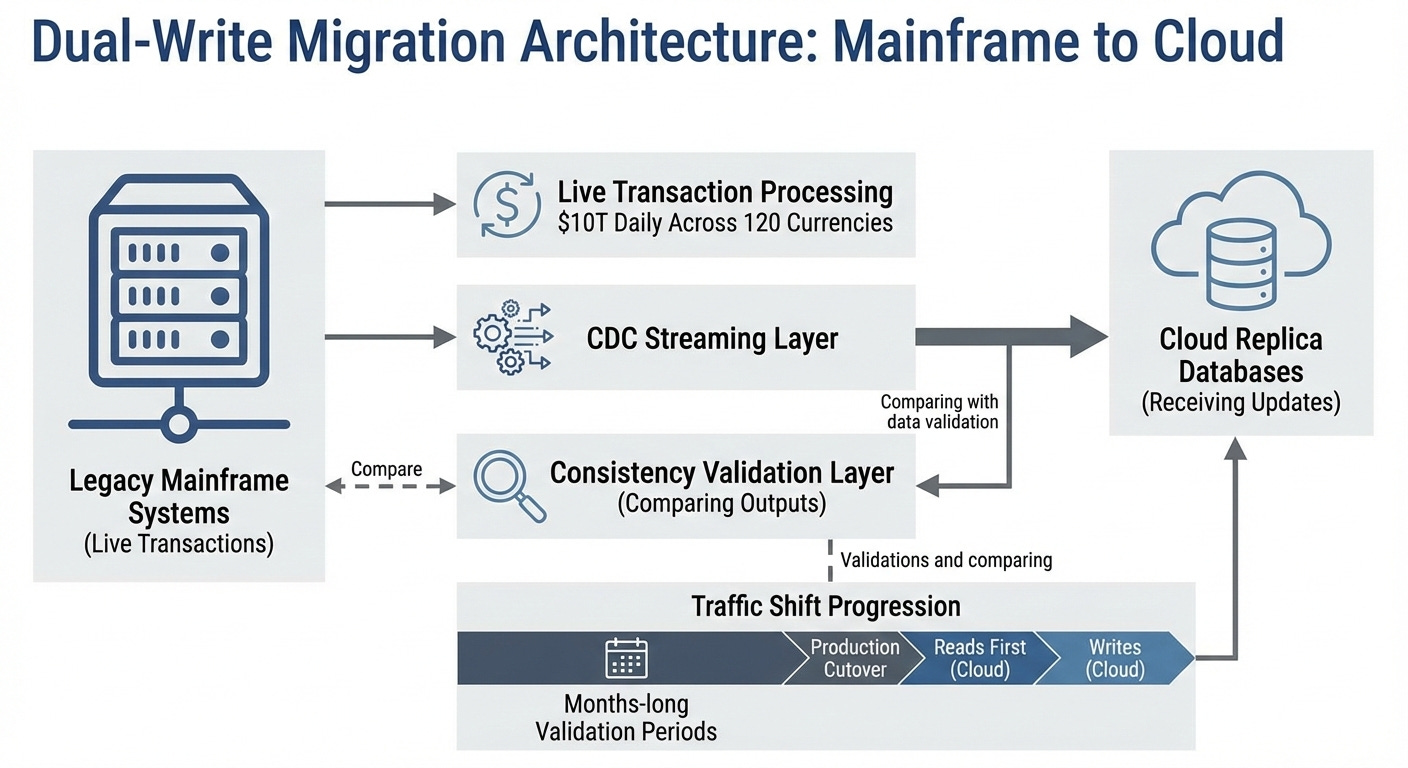
Cloud Migration Strategy: High-Volume Data Systems Transformation
JPMorgan processes nearly $10 trillion in payments daily across 120 currencies. Moving that volume from mainframe systems to cloud infrastructure presents technical challenges most engineers never encounter: dual-write architectures maintaining consistency across legacy and modern systems, schema translation for decades-old data models, and testing strategies that verify correctness without access to production traffic patterns.
The bank increased cloud application deployment from 38% in 2022 to 65% by 2025, with approximately 80% now running on modern infrastructure. That three-year timeline reflects the actual complexity of financial systems migration, not the “lift and shift in six months” narrative common in cloud vendor marketing.
The migration challenge requires running old and new systems simultaneously. JPMorgan uses change data capture technology that copies every transaction from mainframe computers to cloud databases in real-time, like carbon paper, creating a duplicate. Both systems process the same transactions for months while engineers verify that the cloud version produces identical results.
Old mainframe systems store data differently from modern cloud databases. Records from the 1980s use outdated formatting that doesn’t translate directly to today’s standards. A single customer’s information might be scattered across 15 different mainframe files that need to be combined into a single modern database record.
Testing presents unique constraints. Banks cannot experiment with real customer transactions due to regulatory rules. Instead, JPMorgan runs shadow tests where cloud systems process copies of live transactions without affecting actual payments. Engineers compare outputs between old and new systems. Only after weeks of matching results with total precision does JPMorgan shift real traffic to cloud infrastructure.
The bank invested over $2 billion in building cloud data centers with computing power that mainframes cannot provide. Modern fraud detection requires specialized processors that analyze transactions instantly, achieving the 300x speed improvement documented in Part 1, where older systems took 24 hours running overnight batch processes.
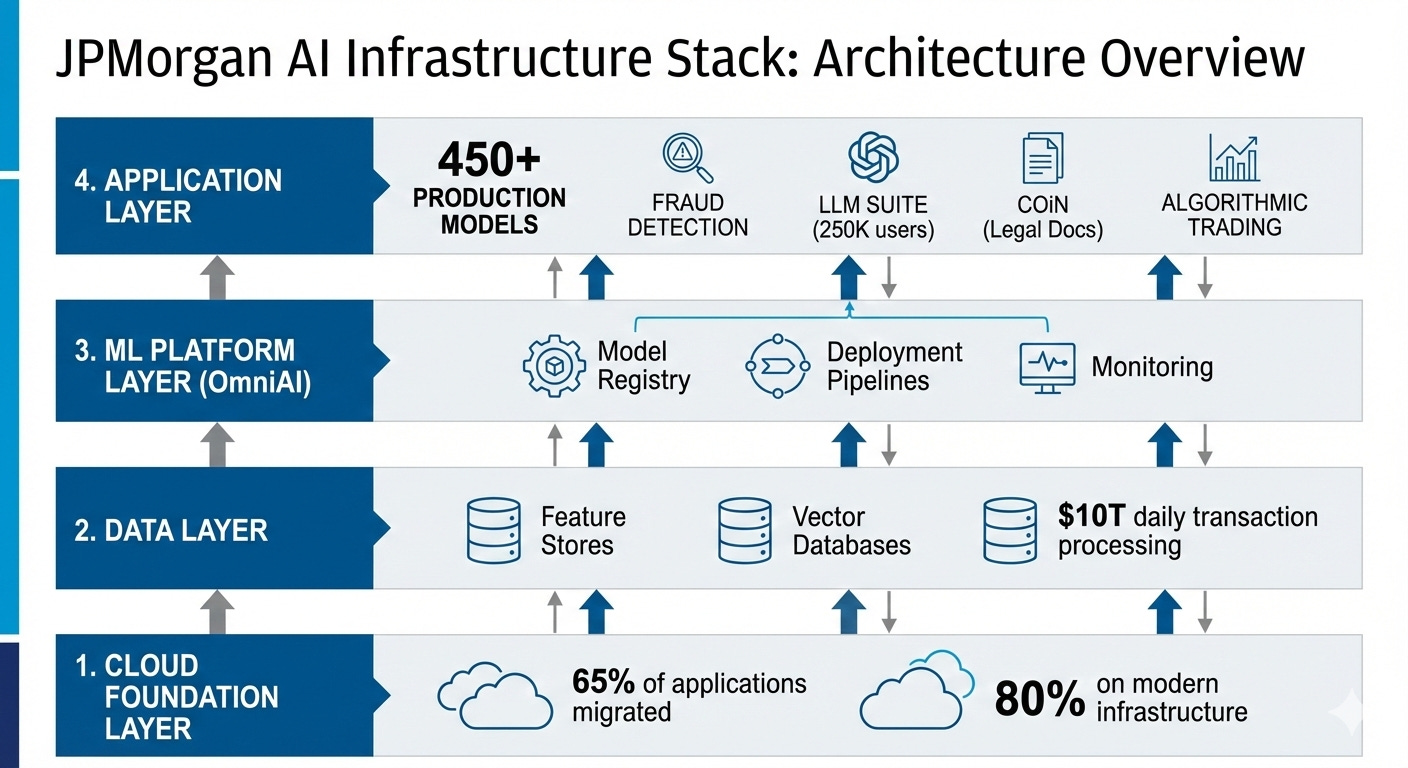
OmniAI Platform: ML Lifecycle Management for 1,700 Specialists
JPMorgan operates OmniAI, an internal ML platform serving 1,700 AI specialists across 450+ production models. The platform addresses problems obscured from organizations running 5-20 models but essential at scale: feature definition inconsistencies that cause training-serving skew, model versioning across teams that independently update shared features, and deployment pipelines that balance engineering velocity and regulatory audit requirements.
Feature stores solve a coordination problem. When different teams build models independently, they often define the same metric differently. One team calculates ‘customer transaction velocity’ over 7 days, another over 30 days. Models trained on one definition but deployed using another produce incorrect predictions.
JPMorgan’s feature store provides a single definition that all teams share. Engineers define each metric once, and the platform ensures every model uses the same calculation for both training and production. This prevents errors where models work in testing but fail in real-world deployment.
The system maintains two versions: a storage system for historical data used in model training, and a fast-access system delivering metrics in milliseconds for real-time predictions. Some metrics update nightly (such as customer credit history), while others update instantly (such as current transaction counts).
Deployment follows a careful progression. New models first run alongside existing models without affecting actual decisions (’shadow deployment’). Engineers compare predictions between old and new versions. Next, new models handle 1-5% of real transactions (’canary deployment’) and are gradually increased if performance remains stable. Automated systems monitor for problems and can reverse deployments if metrics degrade.
Monitoring 450+ models requires tracking whether model predictions remain accurate as real-world patterns change. Each model logs its decisions to a central system. Nightly analysis checks whether current predictions match patterns from training data, alerting engineers when models need retraining.
This platform infrastructure enables JPMorgan’s distributed AI organization: 900 data scientists, 600 ML engineers, and 1,000 data management specialists working across lines of business while maintaining centralized governance. Without OmniAI, coordinating 1,700 specialists across 450+ models would create competing definitions, inconsistent deployments, and regulatory compliance failures.
LLM Suite Gateway: Powering 250,000 Employees
The platform manages multiple AI providers (OpenAI and Anthropic) through a single interface. Employees request AI assistance without choosing specific vendors; the system routes requests based on cost and capabilities. This prevents dependence on any single vendor.
Cost tracking monitors AI usage by person, department, and application. The system records how many ‘tokens’ (roughly equivalent to words) each request consumes, which AI model processed it, and when it was processed. Finance teams receive monthly reports showing AI costs by business unit, enabling budgeting and cost allocation.
The system connects AI models to JPMorgan’s internal documents using retrieval-augmented generation (RAG). When employees ask questions, the system searches millions of internal documents for relevant information, then provides that context to the AI before generating answers. This grounds responses in JPMorgan’s actual policies and data rather than the AI’s general training.
Vector databases enable semantic search across internal documents. Unlike keyword search, which matches exact words, semantic search understands meaning. A search for ‘loan approval process’ finds relevant documents even if they use different terminology, such as ‘credit decisioning workflow.’
Access controls ensure employees only receive information they’re permitted to see. Investment bankers cannot access retail customer data; retail employees cannot access merger documents. The system filters search results based on employee permissions before providing context to the AI.
The eight-week update cadence manages LLM Suite platform changes: evaluation → testing → limited rollout → full deployment. Evaluation assesses new models against existing models using golden datasets (curated question-answer pairs covering common use cases). Limited rollout serves 5-10% of production traffic and monitors for quality degradation. Full deployment occurs only after validating metrics across a limited rollout.
The platform enables measured productivity gains: investment bankers automating 40% of research tasks, portfolio managers cutting research time by up to 83%, and wealth advisors finding information 95% faster.
Real-Time Fraud Detection at $10 Trillion Daily Scale
JPMorgan’s fraud detection operates at millisecond latency while processing $10 trillion in daily transactions. The system achieves 40% higher accuracy than traditional rule-based approaches, enabling real-time blocking of fraudulent transactions before they are completed.
The system must analyze each transaction in milliseconds before completing payment. At $10 trillion in daily volume across 8 billion transactions, JPMorgan processes roughly 93,000 transactions per second on average, peaking above 200,000 during peak periods.
Fraud detection examines dozens of signals: transaction amount, merchant type, location, time of day, account age, typical spending patterns, recent transaction frequency, and connections to known fraudulent accounts. The system computes these signals instantly by maintaining pre-calculated summaries that update with each transaction rather than recalculating from scratch.
The architecture uses streaming technologies (Kafka and Flink) to continuously process transactions. As transactions occur, the system computes risk signals, scores fraud probability, and returns decisions before payments are complete.
Reducing false positives represents the primary challenge. Traditional systems block many legitimate transactions, frustrating customers. JPMorgan’s 40% improvement in accuracy means the system correctly identifies actual fraud while allowing more legitimate transactions through.
The system continuously re-trains on recent fraud patterns. Fraudsters constantly evolve their tactics, making yesterday’s model less effective today. JPMorgan deploys updated models through the same careful progression used for other AI systems (shadow testing, then gradual rollout).
Fraud attacks grow 12% annually. Without AI, fraud losses would escalate exponentially. By holding fraud costs flat despite surging attack volumes, the system avoids hundreds of millions in potential losses, contributing significantly to the $2 billion in annual business value detailed in Part 1. This represents defensive value that’s easily overlooked: preventing losses rather than generating new revenue.
Strategic Maturity: Structural Barriers to AI Replication
Data infrastructure maturity distinguishes successful AI initiatives from failed attempts.
JPMorgan spent a decade building foundations before deploying AI at scale, unifying customer information across 30+ disconnected legacy systems. This unification ensures every department accesses identical customer data. The bank built pipelines moving data from mainframe computers to cloud databases instantly. In contrast, many organizations rely on inconsistent customer records, daily batch updates, and manual error tracking.
Testing requirements reflect banking regulations. JPMorgan must explain every credit decision to regulators, prove fraud models treat all customers fairly, and demonstrate AI systems meet safety standards. Most companies deploy models after basic accuracy testing without rigorous validation or explanation capabilities.
Legacy system integration determines what’s possible. JPMorgan spent years building connections, allowing modern AI systems to interact with decades-old mainframe applications. Companies with similar old systems but without this integration cannot deploy AI, requiring instant access to core data.
The $2 billion in returns comes more from data infrastructure, testing frameworks, and operational systems than from sophisticated algorithms. Any company can buy the same cloud services, use the same open-source software, and hire comparable talent. What cannot be replicated quickly is the decade of data engineering, laying the foundations for deployment.
Organizations should assess their readiness through honest questions: Do you have consistent customer information across all systems, or does marketing see different data than sales? Can you calculate customer metrics instantly, or does data processing take hours? Do you have shared tools preventing teams from defining the same metric differently? Can you test new models safely without affecting customers? Do you monitor whether models stay accurate as conditions change? Can you explain to regulators why models make specific decisions?
Honest answers reveal gaps. Closing them requires multi-year infrastructure investment, producing no immediate revenue. Executives must approve spending millions on data quality tools and deployment automation before the first AI model delivers business value. This patience separates JPMorgan from competitors seeking immediate AI returns.
Part 1 documented JPMorgan’s competitive positioning: the bank ranks #1 on Evident AI’s Index for AI maturity, commands a valuation premium of 2.68x book value versus peers, and outperformed bank indices by 35% in 2025. That market recognition reflects investor confidence that competitors cannot quickly replicate this infrastructure advantage. Wells Fargo, Citigroup, Goldman Sachs, and Bank of America all acknowledge AI investments, but none disclose production use case counts or specific financial returns approaching JPMorgan’s transparency.
Data Infrastructure Foundations: Prerequisites for AI Success
JPMorgan’s $2 billion annual return stems from a technical infrastructure built to handle 450 production models scaling toward 1,000. These results include 40% higher fraud detection accuracy and wealth advisors finding information 95% faster. Such outcomes originate from a decade of foundational engineering rather than the recent adoption of popular algorithms.
Many organizations struggle with AI because they lack foundational data architecture. Without consistent identifiers, real-time pipelines, and automated drift monitoring, data scientists spend 80% of their time on infrastructure maintenance. JPMorgan’s success proves that shifting this ratio through centralized platforms creates a structural lead over competitors.
Technical practitioners should recognize that AI returns require ML operations to be mature, which can take years to build. Organizations starting AI initiatives today must invest in data infrastructure, feature engineering capabilities, deployment automation, and monitoring systems before expecting $2 billion returns. Machine learning models represent a widely available commodity. The infrastructure surrounding those models determines success.
JPMorgan’s AI leadership persists because competitors cannot quickly replicate the data engineering foundation. Regional banks can hire data scientists, but cannot build equivalent data pipelines without a multi-year investment. Fintech startups begin with modern infrastructure but lack transaction data at JPMorgan’s scale.
For executives considering AI investment, JPMorgan’s experience teaches patience. The bank spent years building data infrastructure starting from 300 use cases and $100 million in value (2022) to reach 450+ use cases and $2 billion in value (2025). Expecting immediate ROI from AI initiatives without addressing foundational data quality, infrastructure, and governance challenges leads to failed projects and abandoned strategies.
The future of enterprise AI belongs to organizations willing to invest in infrastructure first and algorithms second. JPMorgan proves the thesis: $2 billion in annual returns from infrastructure that enables 1,700 specialists to operate 450+ models, delivering measurable business value. That infrastructure includes cloud migration, feature stores, deployment pipelines, and monitoring systems.
A special thanks to John Brewton for collaborating on this analysis!
The Data Letter delivers breakdowns like this on the systems and strategies behind the world's most important companies. For deep dives into data infrastructure, MLOps, and the operating models that create billion-dollar advantages, become a paying subscriber.
 | A guest post by
|
This reads like a reminder that AI success is engineered, not announced. Latency budgets, reliability, and integration matter far more than model demos once systems hit production scale. Thank you