
Code w/ Claude
5 data science trends I’m watching

6 MINUTE READ
I’m still thinking about the ideas from the talks at Anthropic’s Code with Claude conference in San Francisco, which I attended last week. Note to self: go to more developer days.
A lot of Code w/ Claude was aimed at software engineers building agents, but if you read between the lines, almost every announcement carries a direct consequence for how we’ll do data science, MLOps, and applied AI work. So instead of summarizing each session, I’ve put together five trends I think are coming for the data scientist role.
1. A 2027 data scientist treats model upgrades as dependency bumps
The clearest theme across the keynotes was a directive to ‘build for the next model’. The teams getting the best results from Claude invest in automated evals, lightweight harnesses, and ambitious prototypes that don’t quite work today, so they’re ready when the next model lands.
For data scientists, this is a familiar idea wearing new clothes. We’ve spent our careers retraining and re-evaluating on rolling windows. What’s different now is the cadence. Anthropic shipped eight frontier models in twelve months. If your data product is wired tightly to the quirks of one specific model version, you’re going to spend 2026 doing migration work instead of building.
The 2027 version of this job looks more like careful pipeline work than reckless shipping. You build evaluation suites that catch regressions automatically, so you can swap in a new model and trust the results before any of it reaches a customer. You keep a list of ideas that are slightly out of reach today, so you can revisit them when the next model jump makes them feasible. Teams that ship safely treat model releases like any other software update. Same review process. Same rollback plan.
2. A 2027 data scientist owns the connections, not the wrappers
A year ago, getting Claude to behave reliably meant writing a lot of supporting code. One of the talks showed how much of that work has now moved into the model itself, so developers no longer have to build it from scratch.
Picking the right tool for a task. Claude now decides which tool to use on its own, reliably enough that hand-written rules get in the way more than they help.
Retrying when tools fail. Claude notices the failure, recovers, and tries again, without a wrapper to babysit it.
Splitting documents into chunks for retrieval. The new million-token context window, paired with server-side memory management, removes the need for most custom retrieval pipelines.
Translating screen coordinates for browser automation. Claude now reads native screen resolutions and clicks the right place without conversion code.
Spinning up servers to run the code Claude writes. Claude now has its own sandbox built in, so it can write code, run it, fix it, and report back, all in one step.
The lesson for data science teams here is that the code you write today to patch model weaknesses will be irrelevant in a few months, because Anthropic will fix those weaknesses in the next release.
The 2027 data scientist spends less time hand-rolling RAG pipelines and retry logic, and more time building integrations into proprietary data and bespoke evaluation harnesses. The plumbing is being commoditized. The data, the evals, and the domain integrations are what stay valuable.
In case you’re new here, here are some recent articles that were very popular with our subscribers:
3. A 2027 data scientist thinks in two scaling axes
For years, the conversation about scaling language models was about training. Bigger datasets, bigger models, more upfront compute. The Code with Claude talk on test-time compute reminded me how much that conversation has expanded. There’s now a second way to scale, and it happens after the model is trained.
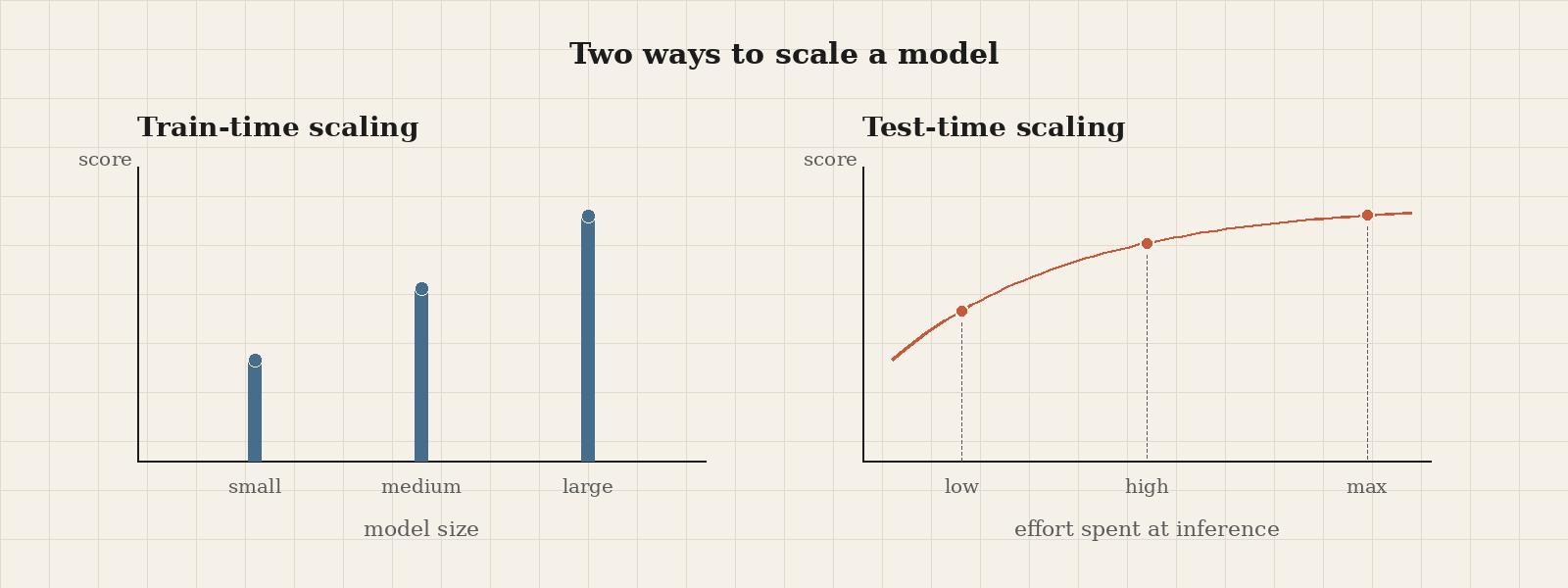
Reasoning models give you a second dial. Spend more tokens at inference, and you can get measurably better outcomes on the same model. Anthropic showed Opus 4.7 running a traffic simulation prompt at low, high, and max effort. At low effort, Claude finished in 50 seconds and produced a basic simulation, with the traffic light awkwardly placed in the middle of the road. At maximum effort, it took ten times longer and used ten times as many tokens, but produced realistic driving behavior, varied car types, and a correctly placed traffic light.
Anthropic also shipped a few new framework pieces. Adaptive thinking lets Claude decide when to think, in what order, and how much to think, instead of forcing a single thinking phase up front. Effort levels (low, medium, high, extra high, max) and task budgets (caps on tokens, time, or cost) let you tell Claude how hard to work and when to stop, so you can trade off cost, latency, and quality on purpose.
For data science, this opens up some interesting design space. You can pick a smaller model with high effort instead of a bigger model with low effort, and the trade-off curves aren’t what you’d expect. When latency matters, a small model gives you the fastest first response. When the final answer matters more than the first token, a larger model running at low effort often finishes the whole task faster than a small model grinding through it. Run your own evaluations across a few effort levels, plot accuracy against tokens spent, and pick the setting where spending more tokens stops paying off.
There’s also an advisor strategy worth flagging, where a smaller model executes while reaching out to a bigger model for advice. One customer hit frontier-quality results at five times lower cost. For high-volume LLM workloads, that pays for itself in a quarter.
The 2027 data scientist evaluates models on two dimensions, size and effort, and reports performance per dollar rather than accuracy alone.
4. A 2027 data scientist curates memory like a feature store
The session on memory and dreaming was the one I keep thinking about. Anthropic released two related capabilities here. The first is memory inside Cloud Managed Agents. Claude treats memory like a folder of files, reading and writing them with the same tools it uses for code. Each store has access controls, full version history, and protection against multiple agents overwriting each other’s notes. The second is Dreaming, a background process that reviews recent agent transcripts, finds patterns and shared mistakes across many sessions, and updates the memory store so the next day’s agents start out smarter.
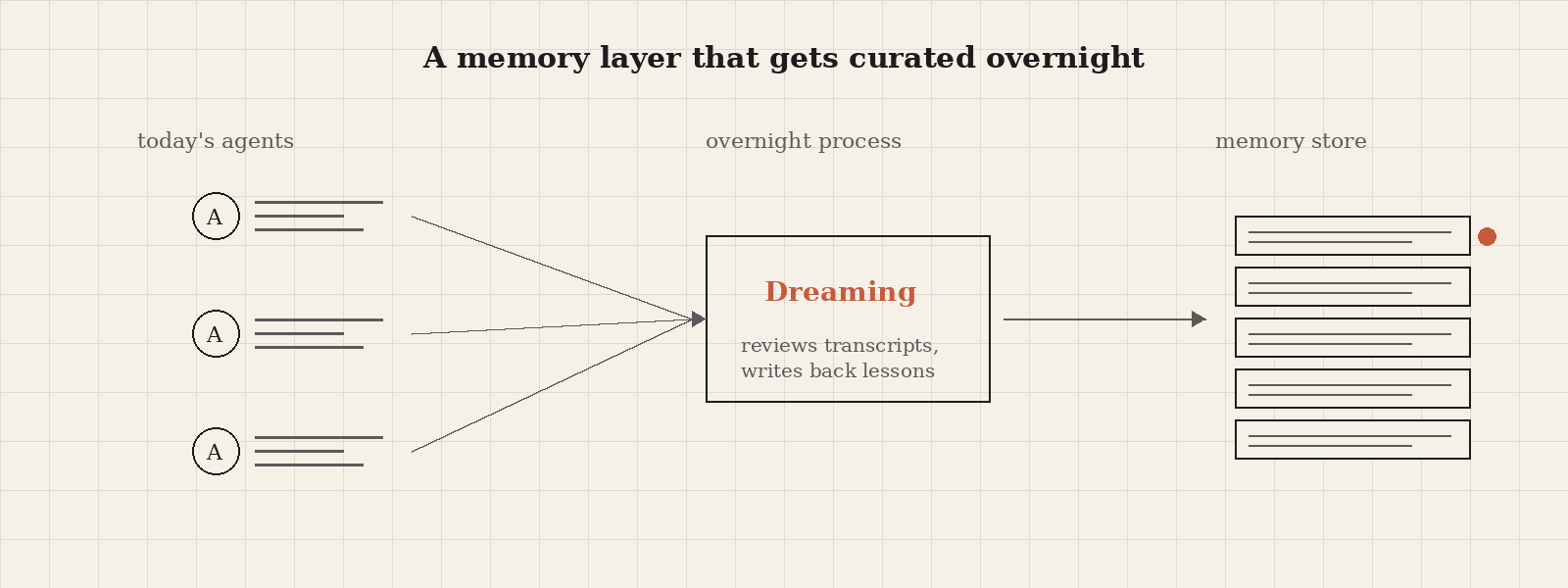
If that doesn’t sound like online learning to a data scientist, I don’t know what does.
One customer saw a sixfold increase in task completion rate on a benchmark after turning on Dreaming. Another customer cut the number of wrong answers their internal AI tools gave employees on the first try by 90%. Same models, but with a memory layer that gets curated overnight.
ML teams now have a new surface to think hard about. Memory raises familiar questions about what to store, how to keep it fresh, who can write to it, and how to share it across teams. The substrate is different from anything we’ve worked with before. Claude reads memory as a folder of files it manages directly, which is a different setup from the vector databases data scientists usually reach for. Familiar retrieval techniques won’t always carry over.
The 2027 data scientist treats memory stores the way we currently treat feature stores. Versioned, observable, owned, with explicit policies for what’s allowed to write and what gets pruned. Whatever we end up calling the role, someone on the team will own this work.
5. A 2027 data scientist runs work in parallel
A few demos showed Cloud Code running sessions in parallel via routines, kicked off by webhooks, schedules, or API calls, with the agent prompting itself rather than waiting for a human. Others showed multi-agent orchestration with a commander coordinating sub-agents, each with its own context window.
A new outcomes feature lets you write a markdown rubric describing success criteria, and the agent iterates until it satisfies the rubric or surfaces a clear failure mode. There are also prebuilt Google Cloud MCP services (BigQuery, Looker, and the Developer Knowledge API), giving Claude direct access to data warehouses and BI tools.
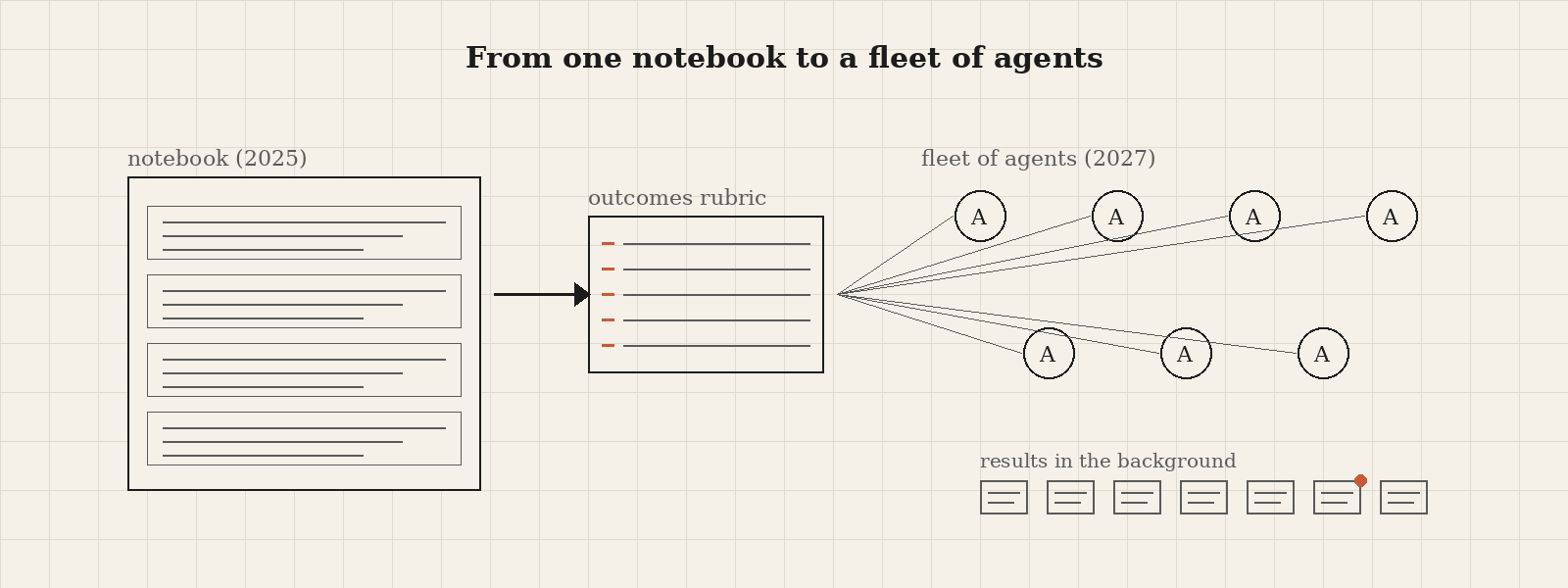
Data scientists already work this way. The work splits naturally into independent threads. Trying different feature combinations, comparing model variants, running evaluations, and exploring different slices of a dataset. We’ve done this work one cell at a time in notebooks because notebooks were the best tool we had.
The new pattern is asynchronous by default. You describe the task, write down what success looks like as a rubric, and a fleet of agents works on it in the background. You come back to a finished result, or a clear failure mode you can debug.
The 2027 data scientist spends less time running cells and more time writing rubrics, reviewing diffs, and curating memory. That’s a different skill mix than what got many hired.
What to do this quarter
If I were running a data science team right now, I’d make 3 moves:
First, audit your eval coverage. If you can’t swap models in a day and re-run, you’re going to fall behind. Hard evals are the moat.
Second, identify one workflow where async multi-agent makes sense and prototype it. Hyperparameter sweeps, multi-model bake-offs, and bulk data quality checks are obvious candidates.
Third, start thinking about memory as a first-class artifact. Even before you deploy a system that uses it, the discipline of writing down what your agents and pipelines should remember between runs will sharpen how you think about reproducibility and learning.
The 2027 data scientist isn’t a different person from the 2025 one. Same instincts about evaluation, same suspicion of overfitting, same love of a clean baseline. The job is just bigger now. We have a second scaling axis to reason about, a memory layer to curate, and fleets of agents to orchestrate instead of notebooks to babysit.
The work ahead is the work data scientists already do well. Evaluating new tools rigorously, building thoughtful pipelines, and knowing when a 10x improvement is a signal versus a fluke.
Two years isn’t long. The data scientists who’ll thrive in 2027 are the ones who started experimenting today.
One more thing. Most data scientists I know are great at the work and terrible at starting it. The 2027 version of this job has more surfaces to manage, more decisions to make, and more opportunities to stall out. That's the exact problem I'm building Asaura AI to solve. It's for high performers who hit paralysis, whether that comes from ADHD, executive dysfunction, a project too big to wrap your head around, or a long day that left nothing in the tank. If any of that lands, Asaura 2 is live.
Everything else is just plumbing that anthropic will eventually replace.