
How to Detect Model Drift When You Can’t Measure Performance

When machine learning models degrade in production, the damage accumulates unnoticed until the business impact becomes undeniable.
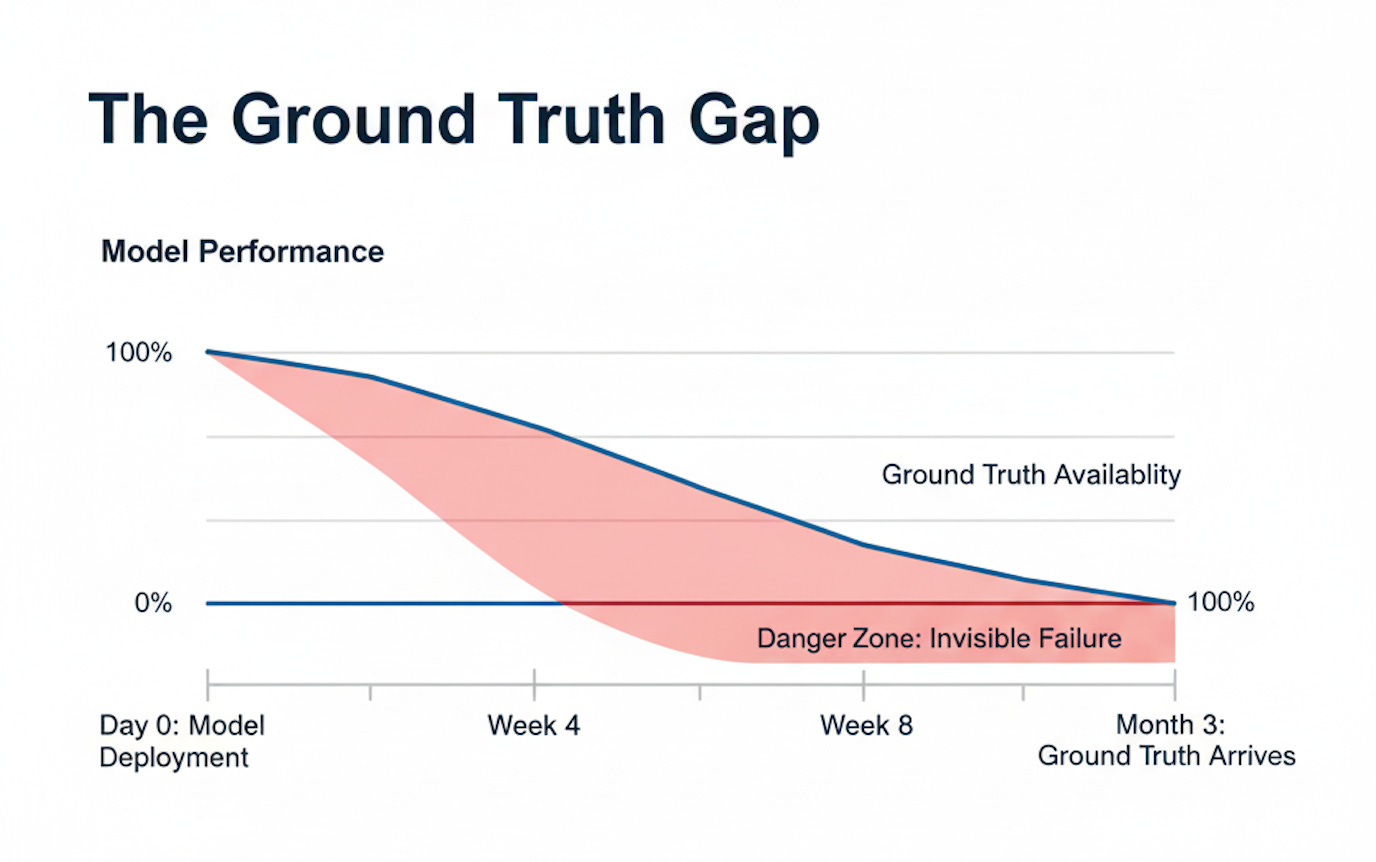
If you’ve been reading The Data Letter for a while, you’ve heard me emphasize this point many times: machine learning models degrade in production, and the damage accumulates until the business impact becomes undeniable. But what does “performance degradation goes undetected” actually mean in practice?
A fraud detection model might take months to confirm which transactions were actually fraudulent. A customer churn predictor can’t measure accuracy until contracts expire. A medical diagnosis system requires follow-up appointments and lab results before validation becomes possible. This pattern appears consistently across production ML systems, regardless of industry or application domain.
Without labels, traditional performance metrics like accuracy, precision, and recall become inaccessible. Waiting weeks or months for these metrics means discovering problems after they’ve already damaged business outcomes, eroded customer trust, and potentially caused regulatory violations.
This article provides the definitive framework and specific methods to build a monitoring system that doesn’t rely on ground truth. You’ll learn how to construct a detection strategy using proxy signals, establish actionable alert thresholds, and implement a production-ready monitoring architecture that identifies problems before they manifest in business metrics.
Drift in Production: Data vs. Concept
Understanding drift requires distinguishing between two fundamentally different phenomena that occur in production systems. These mechanisms operate independently, can occur simultaneously, and demand separate monitoring approaches.
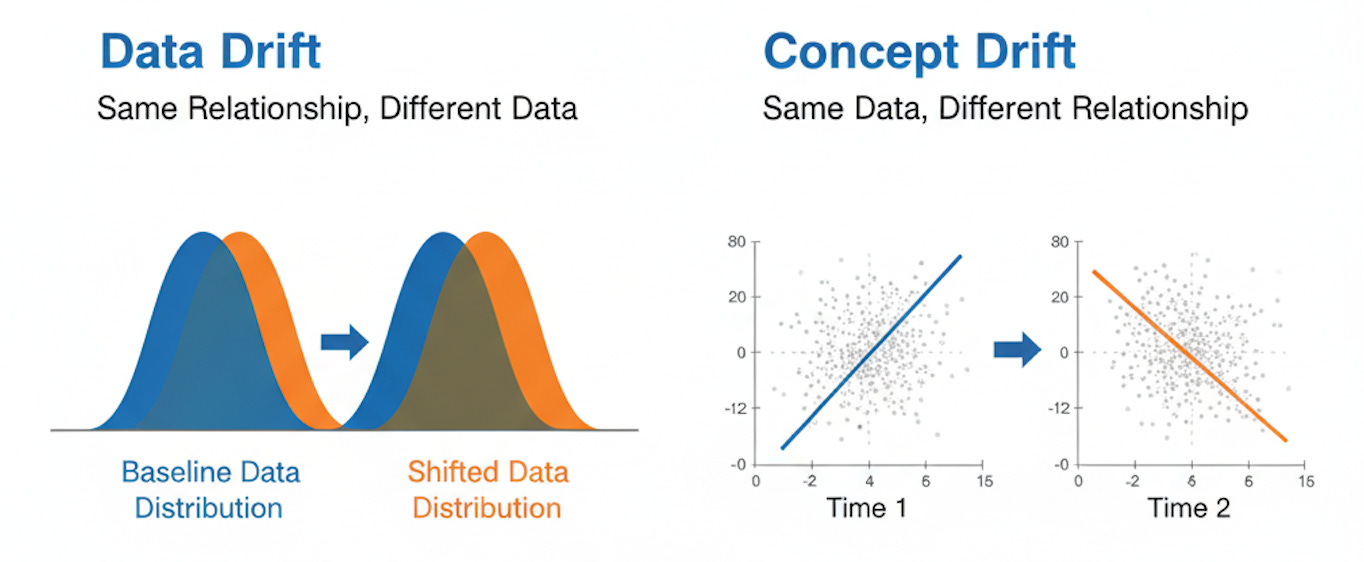
Data drift refers to a change in the statistical distribution of input features. The relationship between features and outcomes remains stable, but the incoming data no longer resembles the training distribution. Consider an insurance underwriting model trained primarily on applications from suburban homeowners in the Northeast. When the company expands into urban markets in the Southwest, the model encounters systematically different property values, construction types, and risk profiles. The statistical properties of the input data have shifted, even though the fundamental relationship between property characteristics and insurance risk remains unchanged.
Concept drift refers to a change in the relationship between the input features and the target variable. The input distributions may remain stable, but the mapping from features to outcomes has evolved. A social media content ranking algorithm exemplifies this pattern. The features describing a post (text length, image count, posting time) might maintain stable distributions, but what users consider engaging content shifts over time. A format that drove high engagement six months ago may now generate indifference. The features haven’t changed, but their predictive relationship to user engagement has fundamentally altered.
These patterns commonly co-occur in production systems. An e-commerce recommendation engine might experience data drift as product catalogs expand into new categories while simultaneously experiencing concept drift as seasonal shopping patterns evolve. A credit scoring model can face data drift from economic shifts affecting applicant demographics, alongside concept drift as lending risk factors change during economic cycles.
Distinguishing between these drift types matters because they require different remediation strategies. Data drift often signals the need to calibrate or adjust feature preprocessing. Concept drift typically requires retraining the model with recent data. Effective monitoring systems must detect both patterns and provide diagnostic information to guide the appropriate response.
Keep reading with a 7-day free trial
Subscribe to The Data Letter to keep reading this post and get 7 days of free access to the full post archives.