
LLM Inference Costs
The 60-80% Problem Nobody Talks About

Training a model costs between $2K and $50K. You pay it once and move on. Inference is different. Every time your model responds to a user, you’re billed again. There’s no finish line.
Inference doesn’t work like that. Inference is a subscription you didn’t fully price. Once a model hits production, inference consistently accounts for 60-80% of total LLM operational spend across a 12-month horizon. For teams shipping to real users at scale, that number trends toward the high end.
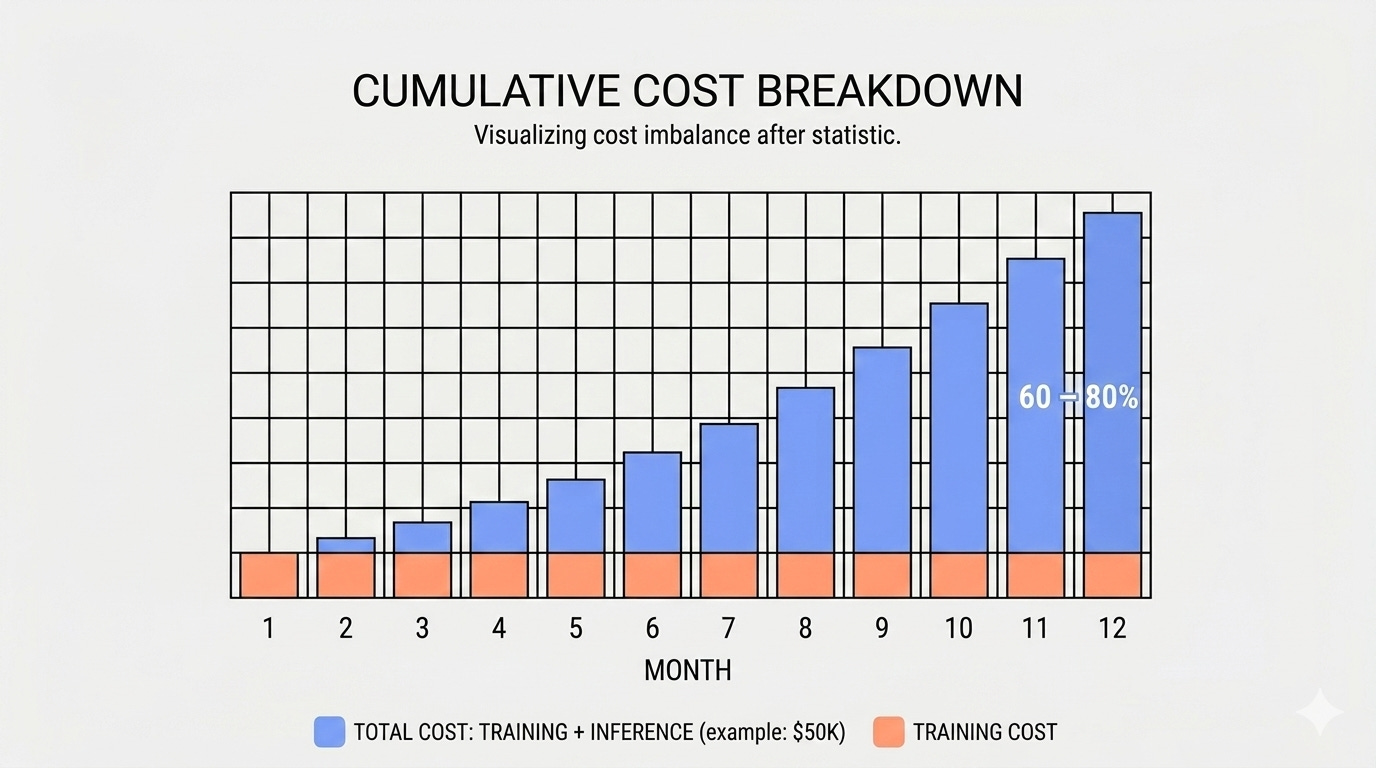
A team that spends $5K on training will often spend $40K-$50K running that model in year one. This happens consistently across production teams.
Inference Costs Catch Production Teams Off Guard
Training has a natural end state. You’re optimizing toward a metric, you hit it, and spending stops. Inference has no finish line. Every user request is a billing event, and billing events compound.
Three mechanisms drive the bulk of that spend:
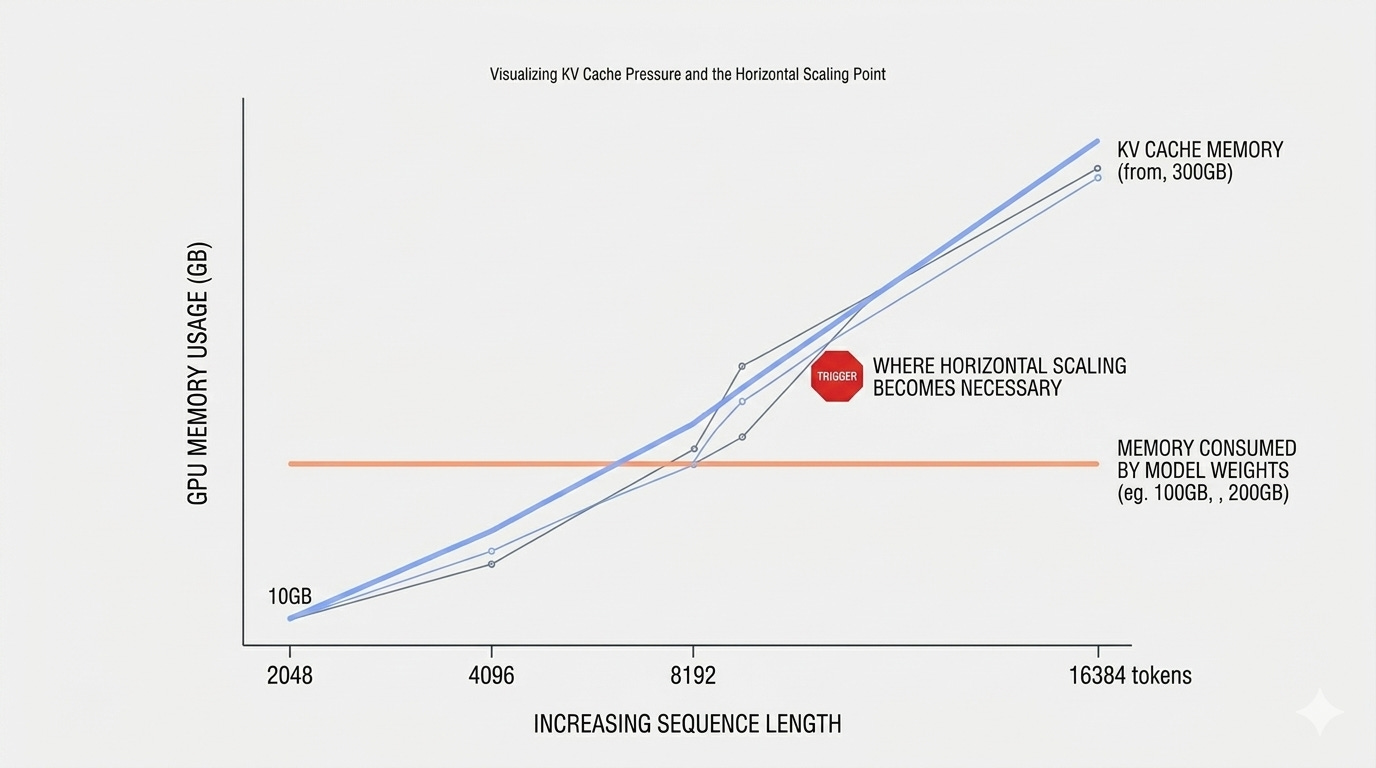
KV cache memory consumption. When your model reads a prompt, it saves a record of every word it processes so it doesn’t have to re-read them for each new word it generates. That saved record is called the KV cache, and it sits in GPU memory. The longer the prompt, the more memory it occupies. For long prompts, 40-60% of your GPU’s available memory can go to KV cache alone.
Idle GPU time. The GPUs powering your model rent for $2-$8/hour, whether they’re processing requests or sitting idle. User traffic isn’t steady; it spikes during business hours and drops overnight, but you can’t spin up a new GPU instantly. Bringing one online takes between one and three minutes, which is too slow to respond to a traffic spike. So teams keep extra GPUs running at all times just in case, and pay for them around the clock.
Per-token economics. Every word sent to the model and every word it sends back costs money. Tokens are just the unit the model uses to measure text, roughly three-quarters of a word each. What teams often miss is how quickly prompt length adds up. A request that includes 2,000 words of retrieved documents, a 500-word system instruction, and a 200-word question costs three to four times as much as a tightly written 700-word equivalent. Bloated instructions, uncompressed retrieved text, and redundant examples all push costs up faster than usage alone would.
Standard Optimizations Don’t Finish the Job
The first instinct is usually to optimize at the model level: quantize to INT8, swap to a smaller model, apply distillation. These are legitimate tools, but they’re not a complete strategy.
Quantization can yield significant savings on its own (up to 50% at INT8 and higher at INT4), but model-routing or batching-only approaches typically plateau at 20-30%, and even quantization’s gains erode if retrieval context and serving efficiency aren’t addressed alongside it. Smaller models help when the workload is simple, but they degrade on complex instructions. Teams frequently apply one of these levers in isolation, see diminishing returns, and assume they’ve hit a ceiling.
They haven’t. The ceiling is generally much higher.
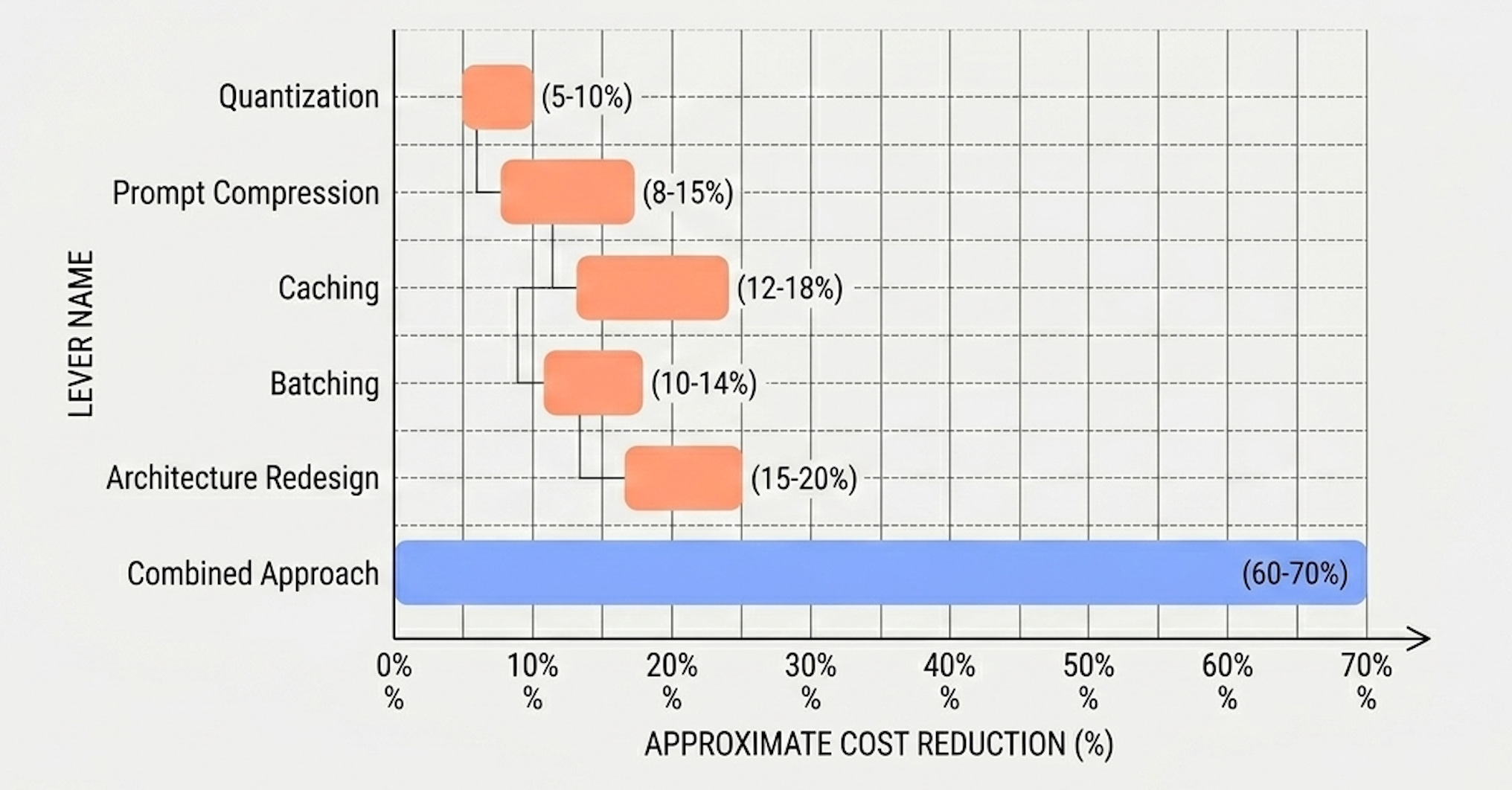
Inference cost reduction isn’t a one-dimensional problem. It spans caching strategy, batching behavior, model selection, serving architecture, and hardware configuration simultaneously. Pulling a single lever and treating it as a complete solution is why teams frequently plateau at 20-30% savings with most optimization approaches, whereas a systematic approach can achieve 60-70%.
How to Know Which Lever to Pull First
The rest of this article walks through five specific optimization levers and the signals that tell you which to prioritize for your workload type.
I also cover a full case study from my most recent client: they were spending $50K/year on inference, and we reduced that to $15K without affecting model quality. Every tradeoff gets named.
LLM Inference Optimization: Cutting Costs by 70% Without Sacrificing Quality
This content is for paid subscribers. If you’re reading this and haven’t upgraded yet, you can do so below.
Keep reading with a 7-day free trial
Subscribe to The Data Letter to keep reading this post and get 7 days of free access to the full post archives.