
Production Hell of AI Agents
Welcome to the Grind

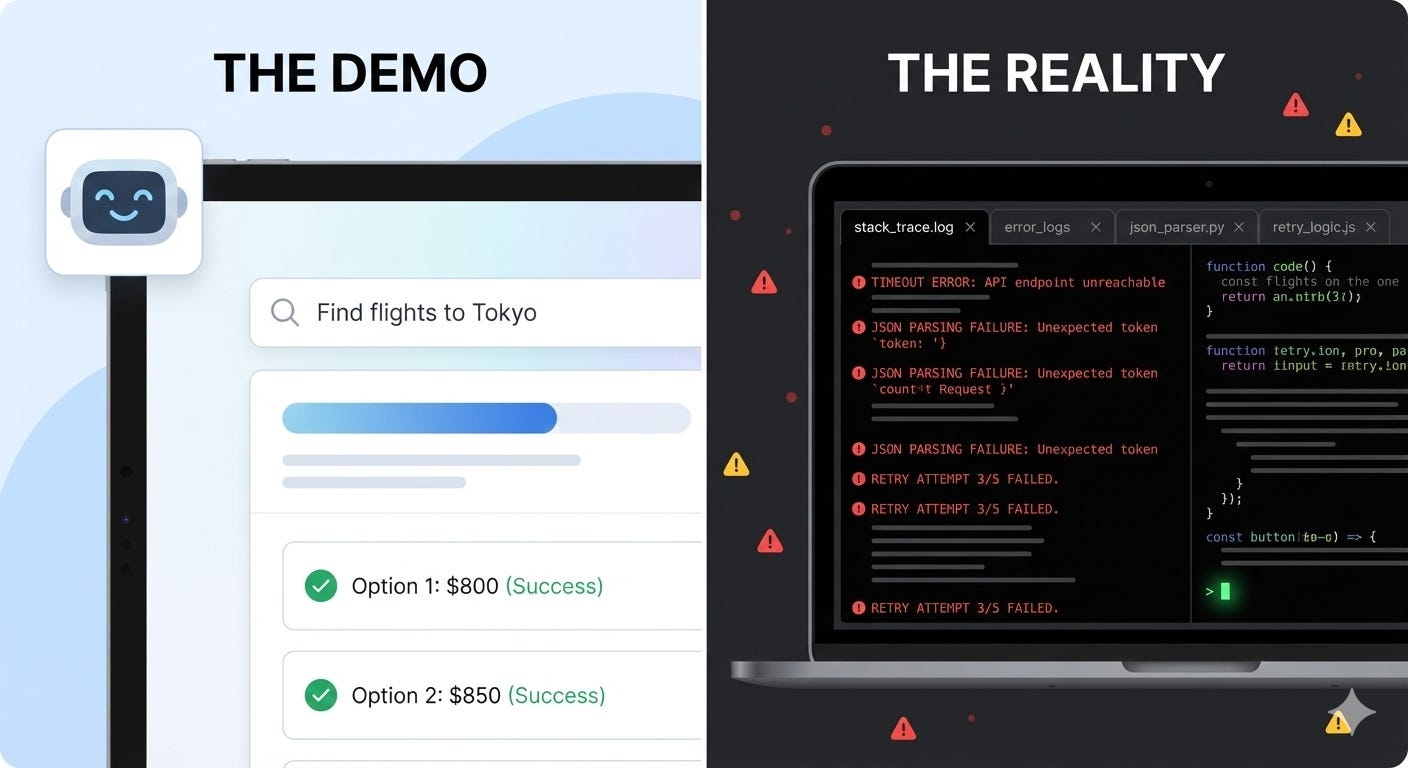
Every promising technology goes through a phase where the gap between prototype and production becomes brutally apparent. For agentic AI, that moment arrived in 2025. The models work. The reasoning capabilities exist. The demos prove feasibility.
What doesn’t exist yet is the operational discipline to make agents reliable at scale. Teams are discovering that building an agent is straightforward. Making it survive contact with real users, real data, and real business constraints is an entirely different engineering challenge.
Welcome to production hell.
This isn't a failure of ambition or technology. It exposes the chasm between demo-stage potential and production-stage engineering requirements. Every team building agentic AI systems encounters this descent: a series of compounding technical, operational, and economic challenges that transform a promising prototype into a reliability nightmare. According to recent surveys, 57% of organizations have agents in production, yet quality remains the top barrier, with 32% citing it as their primary challenge.
Survival requires building a new discipline: agent operations, not waiting for the next model release. They’ll do it through pragmatic design, rigorous observability, and the wisdom to know when a deterministic workflow beats an autonomous agent.
Descending Through Agent Hell: Where Production Dreams Die
Building production-ready AI agents involves overcoming different layers of difficulty, with each layer building on the previous one. Each demands engineering solutions that don’t yet exist in standardized form.
Spiraling AI Agent Costs: When LLM Expenses Devour Your Budget
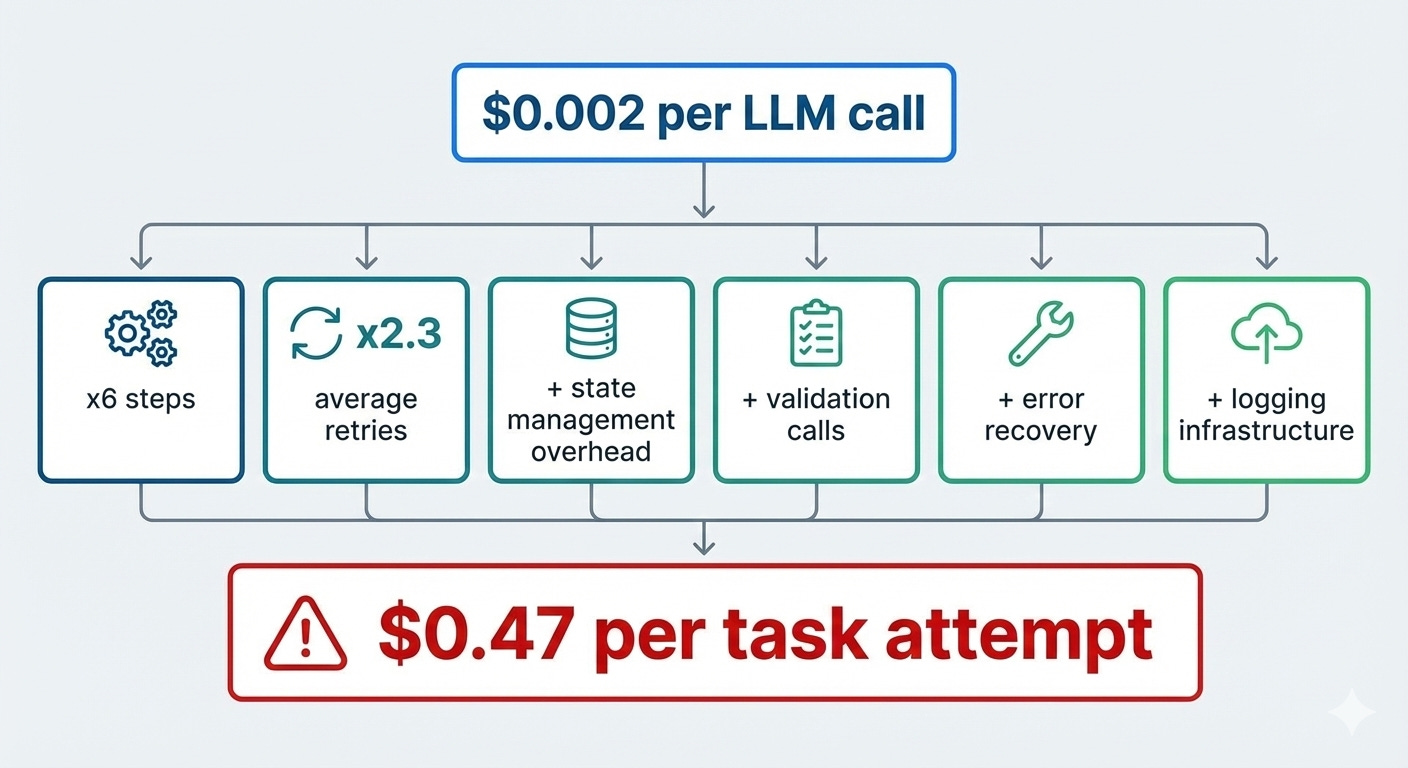
A single GPT-4 call costs fractions of a penny. Then you chain six calls together: planning, tool selection, execution, validation, error recovery, and final synthesis. Now you’re at several cents per task attempt. Multiply by failed attempts. Multiply by the debugging runs that never make it to production.
The economics collapse fast. Production agents orchestrate complex workflows: state management, validation logic, retry mechanisms, and logging systems. Each piece adds cost. Most of these pieces serve as operational overhead to make LLMs semi-reliable rather than LLM calls themselves.
According to industry data, GPT-4 Turbo costs $0.01–$0.03 per 1,000 tokens, and complex agents can burn 5–10 million tokens monthly. For mid-sized deployments, LLM operational costs range from $1,000 to $5,000 per month. Long context windows and chained reasoning multiply costs exponentially. One e-commerce brand saw token usage spike 300% after enabling order-tracking workflows, pushing monthly costs from $1,200 to $4,800.
Research from 2025 shows that 80% of enterprises underestimate their AI infrastructure costs by more than 25%. This is why agent projects stall: the unit economics don’t work until reliability crosses 90%, and that threshold remains elusive.
Debugging AI Agents: Tracing Failures Through Stochastic Fog
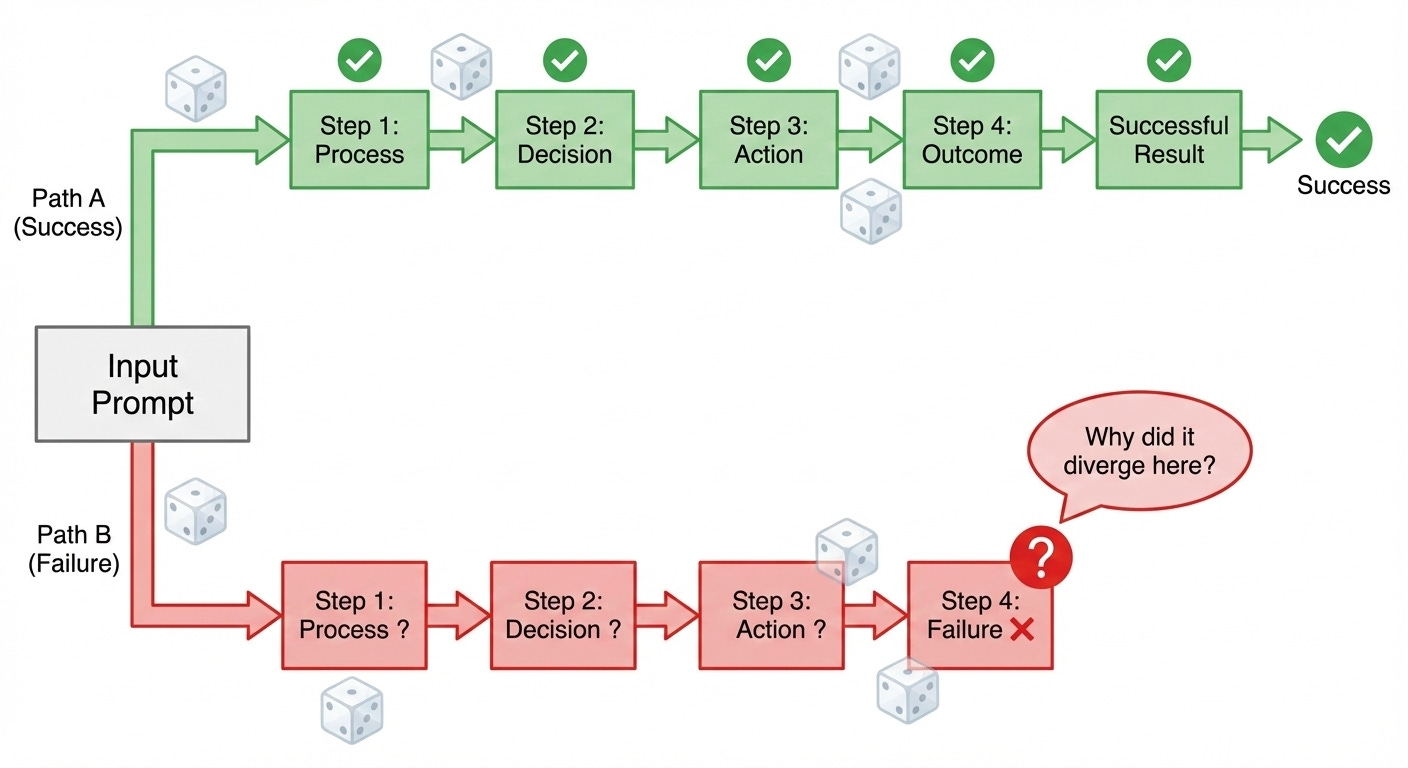
Traditional software fails the same way every time. Same input, same bug, every time. You set a breakpoint, step through the code, find the bad line, and fix it.
Agents behave differently.
Run the same prompt twice, and get two different reasoning paths. One succeeds; the other halts with a malformed JSON response. Which step broke? Was it the prompt? The model’s sampling randomness? An edge case in your validation logic? A transient API timeout that corrupted the state three steps ago?
You have no breakpoints. You have logs: thousands of lines of LLM outputs that read like stream-of-consciousness reasoning, peppered with tool calls and intermediate results. Somewhere in that morass, the agent decided to skip a necessary validation step. Why? The model doesn’t tell you. The logs show it happened, not why.
The community’s recent enthusiasm for models like DeepSeek R1 reflects this pain. DeepSeek R1’s explicit reasoning traces provide unprecedented transparency, exposing the model’s decision process through structured sequences that show problem definition, iterative refinement, and final solution articulation. Engineers want visibility into why the agent chose path A over path B, why it hallucinated a parameter value, and why it decided the task was complete when it clearly wasn’t.
Better reasoning traces help diagnosis, yet they don’t solve the core operational problem. Even with complete visibility, you’re still debugging a stochastic system. The fix for one failure pattern might introduce a new one. Prompt engineering becomes a game of whack-a-mole: patch the issue where the agent misinterprets datetime formats, only to discover it now fails on timezone conversions.
Research shows that DeepSeek R1’s transparent reasoning makes models vulnerable to safety threats and jailbreak attacks precisely because detailed traces expose the full decision-making process. The transparency that aids debugging also increases the attack surface.
You can’t write unit tests for “the agent should reason correctly.” You can write integration tests for specific scenarios, watch them pass, and hope the model generalizes. When it doesn’t, you’re back in the logs, searching for patterns in randomness.
Hitting AI Agent Reliability Ceilings: When Brittleness Wins
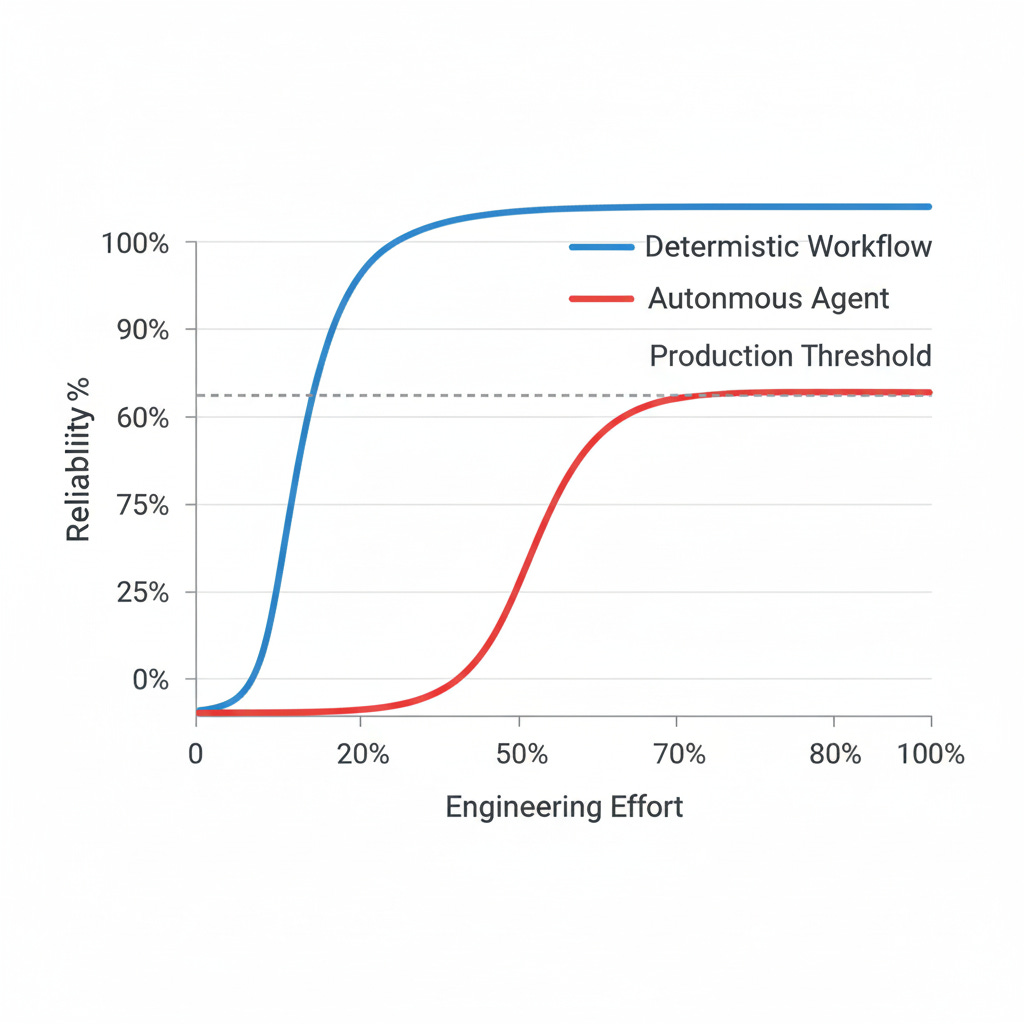
You’ve tuned your prompts. You’ve added validation. You’ve implemented retry logic. Your agent now succeeds 75% of the time. Then you plateau.
No amount of prompt engineering gets you past 80%. The remaining failures are edge cases: ambiguous inputs, unexpected API responses, scenarios that require contextual judgment the model simply doesn’t have. You’re stuck in the reliability gap: good enough to be tantalizing, too unreliable to ship.
In demos, teams rarely mention that a simple decision tree or state machine often beats an autonomous agent on reliability, cost, debuggability, and predictability.
A decision tree with 15 branches costs nothing to run and succeeds 99% of the time. Your clever agent costs $0.30 per attempt and succeeds 78% of the time. Which one ships?
Real-world data confirms this pattern. UC Berkeley found that reliability remains the top development challenge for production agents. Rather than develop technical innovations, developers dial down their ambitions and adopt simpler methods. Most use off-the-shelf models with no fine-tuning and hand-tuned prompts. Agents have short run-times, with 68% executing fewer than 10 steps before requiring human intervention.
Testing of autonomous agents like Devin revealed stark limitations: while they excel at isolated tasks like API integrations, they achieve only 3 successes out of 20 end-to-end tasks. Simpler, developer-driven workflows using tools like Cursor avoid many issues encountered with autonomous agents.
A 5% error rate might be acceptable for a chatbot, but it becomes a massive problem for agents that place orders, update databases, or make automated decisions. One corrupted database entry can shut down operations. The brittleness ceiling forces a brutal reckoning: maybe autonomous agents aren’t the right architecture for this problem. Maybe hybrid approaches combining deterministic workflows with LLM-powered flexibility at specific decision points deliver better outcomes.
Integration Labyrinth: Connecting AI Agents to Real-World Systems
While you’ve been wrestling with prompt reliability, your agent still needs to talk to the outside world. Every real production agent requires integration with existing systems: CRMs, databases, payment processors, internal APIs, and third party services. This is where demo magic dies in a pile of authentication flows and schema mismatches.
Your demo agent “sends an email.” In production, that means:
OAuth 2.0 flow with token refresh logic
Rate limiting that varies by provider
Handling bounces, spam filters, and delivery failures
Parsing varied response formats (JSON, XML, GraphQL)
Managing API versioning when providers change schemas
Timeouts that corrupt the multi-step agent state
Webhook verification for async confirmations
Error codes that mean different things across different APIs
Each integration multiplies the failure modes. Your agent might execute flawless reasoning yet hit errors because the calendar API returned a 429 rate limit, the CRM schema changed and broke your field mapping, or the payment processor requires 3D Secure authentication that your agent can’t handle.
Industry practitioners confirm this is the hardest part of production deployment. One analysis found that the most challenging part of building a production-ready agent is the “body” layer: secure authentication with third-party applications, credential management for thousands of users, and reliable execution via well-formed API calls. This is the time-consuming plumbing that separates a clever prototype from a scalable product.
Authentication complexity alone creates massive overhead. AI agents require robust, automated, and cryptographically secure authentication rather than traditional human-centric methods. Best practices include using short-lived certificates from trusted PKIs, using hardware security modules (HSMs) to store keys, and workload identity federation to tie agent identities directly to organizational infrastructure. Token rotation must happen automatically every 24-72 hours to maintain security.
Engineers spend weeks building resilient connectors, implementing exponential backoff, and writing parsers for inconsistent responses. None of this shows up in demos. All of it determines whether your agent survives contact with production.
The integration layer becomes your agent’s largest codebase, with more lines of defensive error handling than actual agent logic. You realize you’re building a traditional distributed system that happens to have an LLM in the middle, with all the operational complexity that entails.
Voices from the Production Trenches: Community Sentiment on AI Agent Challenges
The disillusionment is widespread and well-documented. Across engineering communities, two narratives emerge repeatedly:
Engineers Pursuing Solutions: 89% of organizations have implemented some form of observability for their agents, and 62% have detailed tracing that allows them to inspect individual agent steps. Without visibility into how an agent reasons and acts, teams can’t reliably debug failures, optimize performance, or build trust with stakeholders.
The enthusiasm for transparent reasoning models like DeepSeek R1 reveals how starved teams are for debuggability. Engineers know the problems are solvable; they need the right instrumentation.
Business Anxiety: Organizations face significant obstacles in translating agentic pilots into deployable solutions. Even among enterprises with agents in production, maturity remains low. Only 5% of engineering leaders cited accurate tool calling as a major challenge, suggesting most production systems focus on surface-level behavior rather than deeper reasoning.
The gap between promised business value and delivered reliability creates existential pressure. According to MMC Ventures data, 42% of organizations deployed at least some agents in Q3 2025, up from 11% two quarters prior, yet 68% of employees interact with agents in fewer than half their workflows. Higher accuracy correlates with lower production autonomy. Healthcare founders report 90% accuracy rates but admit this isn’t sufficient to remove human oversight.
Teams are frustrated, not defeated. They’re sharing workarounds, comparing architectures, and debating hybrid approaches. Production hell is painful, but it’s where real engineering disciplines are forged.
Standardizing Agent Infrastructure: AAIF’s Emerging Role
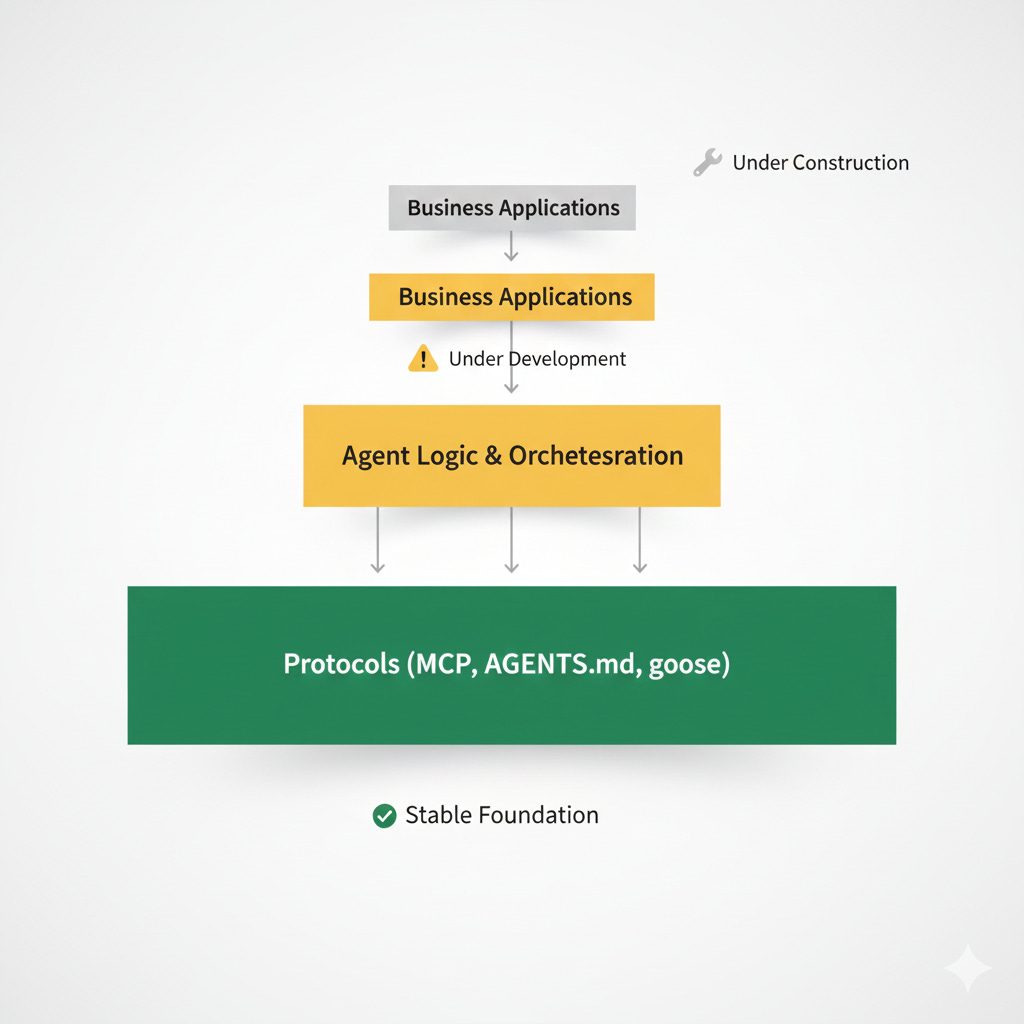
While teams struggle with production challenges, the industry is standardizing the infrastructure layer that could ease the pain. In December 2025, the Linux Foundation announced the Agentic AI Foundation (AAIF), bringing together Anthropic’s Model Context Protocol (MCP), Block’s goose, and OpenAI’s AGENTS.md under neutral governance.
This represents a strategic recognition: agent execution infrastructure, not model capabilities, currently blocks progress. MCP alone went from an internal Anthropic project to an industry standard in 12 months, with over 10,000 published servers now connecting agents to tools, data, and applications. The protocol has been adopted by Claude, Cursor, Microsoft Copilot, Gemini, VS Code, and ChatGPT.
The formation of AAIF, backed by platinum members including AWS, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, and OpenAI, signals that the unstructured experimentation phase is coming to an end.
For engineers in production hell, this standardization offers a path forward. Rather than building custom integration layers for every external system, teams can build on MCP’s universal connection standard. Rather than inventing project-specific agent guidance, they can adopt AGENTS.md’s Markdown convention, already used by over 60,000 open-source projects.
Teams now face a different question: “How do we make this work reliably within established protocols?” That’s still hard, but it’s engineering hard, not research hard.
Survival Guide: Engineering Your Way Out of AI Agent Production Hell
Production hell ends when you stop fighting the fundamental nature of LLMs and start building systems that account for their limitations. Here’s how teams are escaping:
Prioritize Deterministic Workflows Over Autonomous AI Agents
Start with the hardest question: Does this problem actually need an agent? Map your workflow. Identify which steps truly require flexible reasoning. You’ll often find 80% of your logic is deterministic and well-suited for state machines or decision trees.
Build that deterministic skeleton first. Use LLMs only for genuinely ambiguous decision points: parsing unstructured user input, choosing between semantically similar options, and generating natural language responses. This hybrid architecture delivers:
Predictable behavior for most cases
Debuggable logic flows
Cost control (LLM calls only where needed)
Clear failure boundaries
Production data validates this approach. Analysis shows that prompt and sequence lengths are steadily growing for programming use cases, while all other categories remain stagnant. Agent builders are keeping their agents simple and short to achieve reliability. Outside of coding agents, prompt and sequence complexity remain stagnant. These simpler agents are the ones reaching production.
An agent that’s 40% state machine and 60% LLM-powered flexibility often outperforms a 100% autonomous agent on every production metric.
Design AI Agents for Human Oversight from Day One
Autonomous agents are a goal, not a starting point. Systems built for production assume human intervention and design for it gracefully. Research confirms that 92.5% of in-production agents deliver their output to humans, not to other software or agents. Chatbot UX dominates because it keeps a human in the loop.
Key strategies include:
Confidence thresholds: When the agent’s certainty drops below a threshold, escalate to human review before proceeding
Preview and confirm: Show users the agent’s planned actions before execution, especially for high-stakes operations
Intervention points: Build explicit handoff mechanisms where humans can step in, correct course, and hand back to the agent
Audit trails: Log every decision and action in a human-readable format for post-hoc review
Companies emphasize “co-pilot positioning” even when full autonomy is technically possible. They discovered employees either overrely or underrely on outputs, never achieving optimal collaboration. Winners aren’t building autonomous systems; they’re building narrow, high-frequency task executors with human oversight.
Measure “mean time to human intervention” as a key metric. You want this number trending down over time, but you never want it to reach zero. That signals you’ve eliminated necessary oversight.
Build AI Agent Observability Before Scaling Logic
You can’t fix what you can’t see. Before adding more sophisticated agent behaviors, instrument everything. The importance of this cannot be overstated: 89% of organizations with agents in production have implemented observability, and adoption is even higher (94%) among those with mature deployments.
Essential observability components:
Structured logging: Every tool call, every reasoning step, every state transition gets logged with context
Distributed tracing: Track requests across the entire agent execution path, including external API calls
Evaluation frameworks: Build automated tests that run your agent against a growing suite of real-world scenarios, not just happy paths
Failure classification: Tag and categorize every failure mode so you can identify patterns
For production agents, teams typically track a mix of quality and performance metrics, including accuracy, task completion rate, latency, error rate, and resource usage. For many customer-facing flows, teams aim for high-90s accuracy on core tasks, completion rates above 90%, sub-second response times for simple interactions, and low single-digit error rates.
Teams that build observability first can iterate rapidly. Teams that bolt it on later spend months retrofitting logging into complex agent logic.
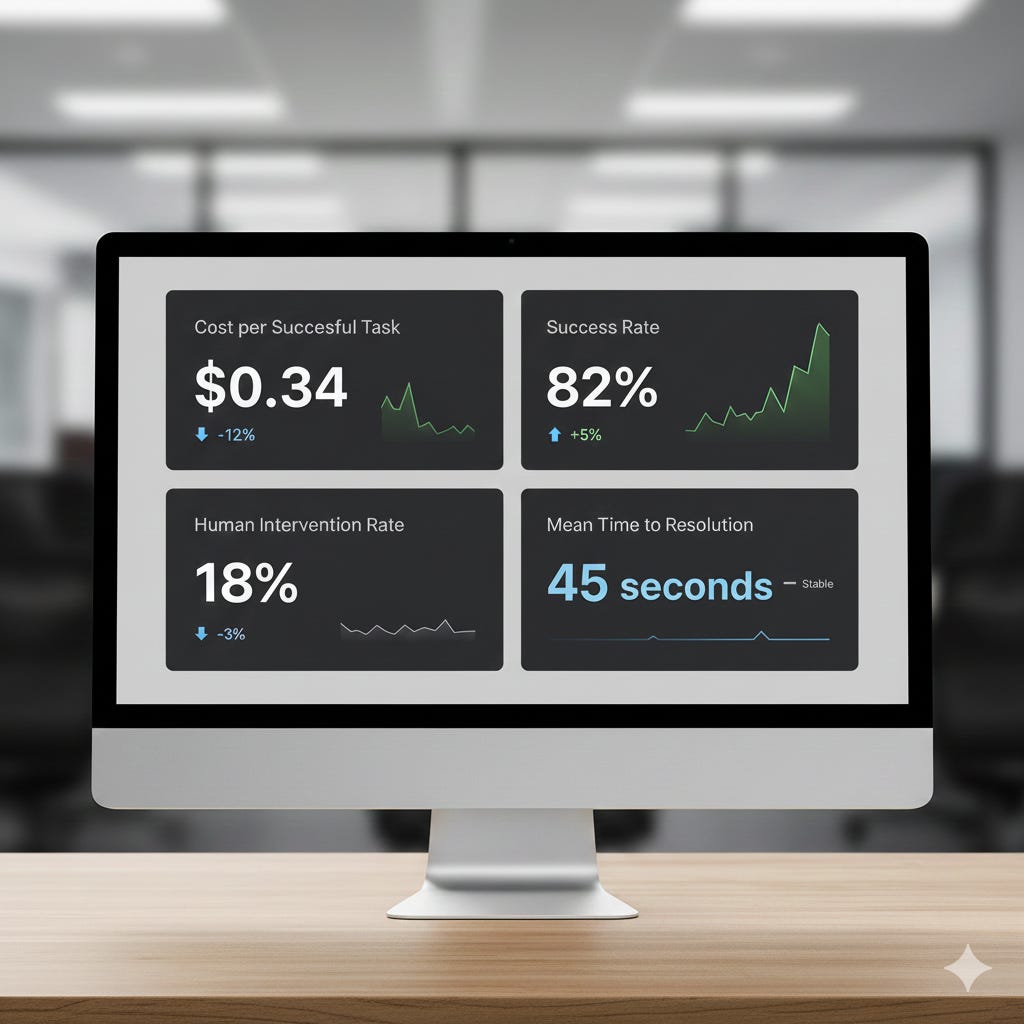
Measure AI Agent Operational Metrics, Not Just Model Performance
Forget about vibes. Track metrics that connect to business outcomes:
Cost per successful task: Total spend (LLM + infrastructure) divided by tasks completed successfully
Success rate by task complexity: Segment simple vs. complex tasks to understand where brittleness lives
Retry rate: How often does the agent need multiple attempts to complete a task?
Human intervention rate: What percentage of tasks require human oversight or correction?
Time to resolution: How long does the full task take, including retries and interventions?
These metrics tell you whether your agent is getting more reliable and cost-effective over time. They also give you the data to make architectural decisions. Research shows that enterprises face $50,000 to $200,000 in integration costs and take 3-6 months to deploy production agents. Without clear operational metrics, it’s impossible to determine if this investment is worthwhile.
One analysis found that startups claiming broad autonomy inevitably pivot to narrow, high-accuracy verticals. Infrastructure costs force model selection trade-offs. High-regulation industries lock into 90% accuracy, 40% autonomy configurations. Others optimize for 70/70 configurations with lower costs.
Production Hell Forges Better Engineering Practices for AI Agents
Production hell feels like failure. Demos worked. Prototypes impressed stakeholders. Then reality intervened.
But this phase matters more than the demo ever did.
Right now, engineers worldwide are learning which agent architectures survive contact with production. They’re discovering that hybrid workflows beat pure autonomy. They’re building observability tools that make stochastic systems debuggable. They’re developing operational metrics that connect AI capabilities to business value. They’re establishing patterns for human-agent collaboration that acknowledge the limitations of current models while leveraging their strengths.
This is how new engineering disciplines are born. Not from triumphant product launches, but from the grinding work of making unstable technology stable. The teams enduring production hell today are writing the playbooks others will follow tomorrow.
The defining story of 2025 was not which models topped benchmarks, but which organizations successfully moved from experimentation to scaled production. Three barriers consistently prevented pilots from reaching production: reliability requirements (a 5% error rate becomes massive for agents making automated decisions), integration complexity (integrating with Oracle, Salesforce, legacy databases, security protocols, and compliance requirements often exceeded expected value), and cost-benefit analysis (proving ROI at scale).
The next generation of agentic applications won’t emerge from better models alone, though better models will help. They’ll emerge from the operational practices being forged right now: knowing when to use agents and when to use state machines, building for human oversight rather than pure autonomy, and measuring operational reliability rather than demo polish.
Production hell reveals that polished demos and deployable systems require fundamentally different engineering approaches.
Your agent will fail. Your agent will fail. The question is whether you’ve built systems to understand why, fix it, and prevent it from happening again. That capability, not model performance, determines whether you ship or stall.
Stay ahead of the shift in agent infrastructure.
Subscribe for in-depth analysis of production AI systems, protocol standards, and the teams building reliable agents at scale.
References
LangChain. “State of AI Agent Engineering 2025.” November-December 2025. https://www.langchain.com/state-of-agent-engineering
AgentiveAIQ. “AI Agent Cost Per Month 2025: Real Pricing Revealed.” August 2025. https://agentiveaiq.com/blog/how-much-does-ai-cost-per-month-real-pricing-revealed
Greenice. “AI Agent Development Cost 2025: Expectation vs Reality.” October 2025. https://greenice.net/ai-agent-development-cost/
Emergent Mind. “DeepSeek-R1 Reasoning Traces.” 2025. https://www.emergentmind.com/topics/deepseek-r1-reasoning-traces
Drew Breunig. “Enterprise Agents Have a Reliability Problem.” December 2025. Analysis of UC Berkeley’s MAP research and other 2025 agent studies. https://www.dbreunig.com/2025/12/06/the-state-of-agents.html
Carl Rannaberg. “State of AI Agents in 2025: A Technical Analysis.” Medium, January 2025. https://carlrannaberg.medium.com/state-of-ai-agents-in-2025-5f11444a5c78
Arion Research. “The State of Agentic AI in 2025: A Year-End Reality Check.” December 2025. https://www.arionresearch.com/blog/the-state-of-agentic-ai-in-2025-a-year-end-reality-check
Composio. “The 2026 Guide to AI Agent Builders (And Why They All Need an Action Layer).” December 2025. https://composio.dev/blog/best-ai-agent-builders-and-integrations
Obsidian Security. “Security for AI Agents: Protecting Intelligent Systems in 2025.” November 2025. https://www.obsidiansecurity.com/blog/security-for-ai-agents
Obsidian Security. “The 2025 AI Agent Security Landscape: Players, Trends, and Risks.” November 2025. https://www.obsidiansecurity.com/blog/ai-agent-market-landscape
Local AI Zone. “DeepSeek AI Models 2025: Revolutionary Reasoning AI for Education & Research.” October 2025. https://local-ai-zone.github.io/brands/deepseek-ai-coding-expert-guide-2025.html
Machine Learning Mastery. “7 Agentic AI Trends to Watch in 2026.” January 2026. https://machinelearningmastery.com/7-agentic-ai-trends-to-watch-in-2026/
Cleanlab. “AI Agents in Production 2025: Enterprise Trends and Best Practices.” August 2025. https://cleanlab.ai/ai-agents-in-production-2025/
TechUpkeep. “The Uncomfortable Truth About AI Agents: 90% Claim Victory While 10% Achieve Adoption.” Analysis of MMC Ventures data. November 2025. https://www.techupkeep.dev/blog/state-of-agentic-ai-2025
Maxim AI. “Understanding AI Agent Reliability: Best Practices for Preventing Drift in Production Systems.” November 2025. https://www.getmaxim.ai/articles/understanding-ai-agent-reliability-best-practices-for-preventing-drift-in-production-systems/
Thammineni, Prasad. “The Complete Guide to AI Agent Pricing Models in 2025.” Agentman, Medium. January 2025. https://medium.com/agentman/the-complete-guide-to-ai-agent-pricing-models-in-2025-ff65501b2802
The Linux Foundation. “Linux Foundation Announces the Formation of the Agentic AI Foundation (AAIF), Anchored by New Project Contributions Including Model Context Protocol (MCP), goose and AGENTS.md.” December 9, 2025. https://www.linuxfoundation.org/press/linux-foundation-announces-the-formation-of-the-agentic-ai-foundation
This was such a great breakdown of the reality of implementing agents! The reliability issues can make improving performance a real challenge. It also gets especially difficult when you can't accurately diagnose why the agent is failing at certain tasks.
Excellent piece Hodman.