
Prompt Engineering.
Treating LLM Prompts as Software Assets

Ad-hoc prompting has a shelf life. It works fine when one person owns a single prompt and checks it regularly. It breaks down when three engineers are touching the same prompt string in different files, nobody’s tracking what changed, and malformed outputs are the first sign that something went wrong. At that point, the prompting is the least of your concerns. What’s missing is basic software management.
Why Ad-Hoc Prompting Breaks at Scale
Ad-hoc prompting works fine for prototypes. You’re iterating fast, the model’s responses are good enough, and the cost is trivial. When a prompt is serving real users under real SLAs with real billing attached, the economics look very different from a prototype.
A prompt is a dependency, just like a library version or a database schema. When it changes, outputs change. When outputs change, downstream parsers, classifiers, and user interfaces can break. Teams that don’t version control prompts lose institutional knowledge, can’t reproduce bugs, and have no rollback path.
The compounding factor is model updates. When using AI via third-party APIs, the LLMs behind those APIs can unexpectedly change. Like traditional ML models, LLMs can be refreshed or tuned without a significant version bump, meaning the model’s performance on your set of prompts can change without any notice. Without a versioning system, you can’t determine whether a degradation came from a prompt change or a model change, and that ambiguity is expensive.
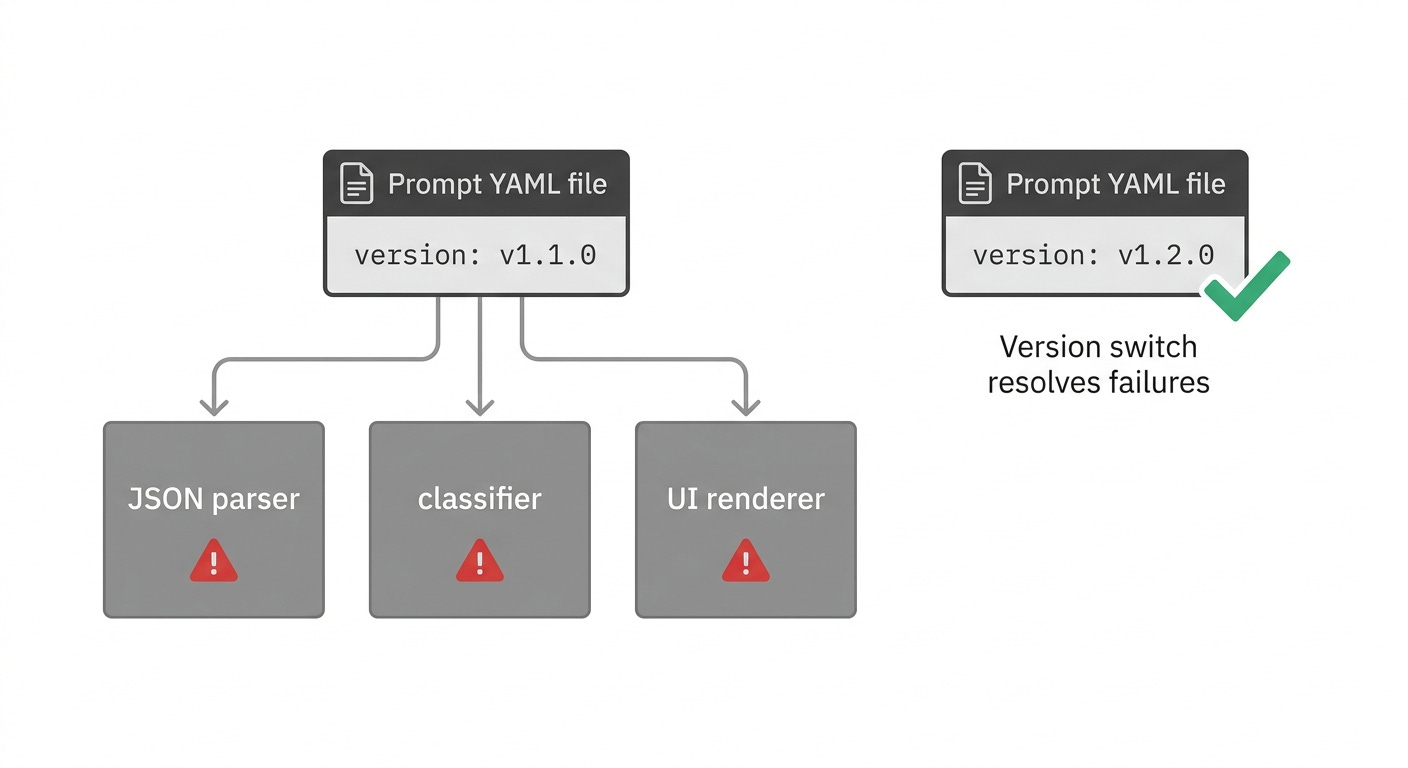
Prompts Drift Like Code
Software engineers have spent decades building systems to manage code drift: version control, branching strategies, code review, CI/CD. Prompts need the same discipline, and most teams apply almost none of it.
There’s an unavoidable tension between keeping prompts close to the code versus an environment that non-technical stakeholders can access. Leaving it unresolved gets more expensive as the team grows.
Prompt management tools from observability platforms like Arize, Braintrust, and LangSmith offer Git-like version control for prompts and allow rollback if changes reduce quality, but tools alone won’t help if the discipline isn’t there. Prompt management tools are inherently limiting because they can’t easily execute your application’s code. Even when they can, there’s often significant indirection involved, making it difficult to test prompts with your system’s full capabilities, including tools, RAG, and agents. Keeping prompts in the same repository as application code, with the same review gates, removes that indirection.
A prompt change is a logic change. It controls what your system does and how it responds, and it deserves the same review process as any other change to your codebase.
Testing Prompts vs. Testing Code
Testing code is relatively well understood. You write unit tests, integration tests, and end-to-end tests. Give a traditional function the same input twice, and you’ll get the same output twice, which makes it straightforward to write tests that check for exact results.
Prompt engineering is about conditioning a probabilistic model to generate a desired output. Each additional instruction or piece of context steers the model’s generation in a particular direction. That probabilistic nature means you can’t assert exact outputs. Instead of checking for an exact answer, you check whether the response has the right shape: whether it’s valid JSON, whether the label the model chose is one you’d accept, and whether the thing it extracted actually appeared in the source text.
Structured evaluations tell you whether a prompt change made things better or worse before it reaches users. Without them, you’re iterating on feel, which works fine until something goes wrong in a way you didn’t anticipate and can’t reproduce.
Eyeballing is useful as a final check, but it doesn’t hold up at volume or across teams.
When Prompt Engineering Pays Off (and When It Doesn’t)
Before committing engineering resources to a prompt infrastructure, it’s worth being honest about ROI.
Prompt engineering pays off when a model’s output goes directly into another system without a human reviewing it first, when the same prompt runs thousands of times a day, when each call carries a meaningful cost, or when output quality has a direct and measurable effect on what users experience. Without reliable evaluation, you can’t iterate, and without iteration, you can’t improve. Projects stall here more than anywhere else in the LLM lifecycle.
For tasks reviewed by humans before use, or where call volume is low enough that failures surface quickly, a lightweight log of prompt versions in a shared document may be sufficient. For anything in the first category, treating prompts as software assets is worth the investment.
In the next section, we get into the practical architecture: how to structure and version prompts, how to run A/B tests without exposing users to untested changes, how to build a test suite that runs automatically when a prompt changes, how to organise a prompt library across a growing team, how to track cost at the prompt level, how to detect when a deployed prompt starts degrading, and two failure patterns that illustrate what happens when these systems aren’t in place.
Keep reading with a 7-day free trial
Subscribe to The Data Letter to keep reading this post and get 7 days of free access to the full post archives.