
Your First Breeze
A Beginner’s Guide to Airflow DAGs

You’ve heard the term. You know it’s the backbone of data engineering. You’ve maybe even seen a cryptic diagram of boxes and arrows, but what is an Airflow DAG, really?
If you’re staring at a blank canvas and don’t know how to make that first brush stroke, you’re in the right place. Today, we’re breaking down the fundamental unit of Airflow work: The Directed Acyclic Graph, or DAG. By the end of this guide, you’ll understand its core components and have written your first functioning data pipeline.
What is a DAG, Anyway?
Let’s demystify the acronym:
Directed: Tasks have a relationship; they point to each other, defining a flow. Task A must run before Task B can start. This direction matters.
Acyclic: This is the golden rule. The flow cannot loop back on itself. Task B cannot, directly or indirectly, be traced back to Task A. This prevents infinite loops and ensures your pipeline will eventually complete.
Graph: It’s a set of nodes (your tasks) and edges (their dependencies) that form a structure.
An Airflow DAG is a blueprint for a data workflow. Its primary role is to orchestrate your workflow, determining the precise when and how your individual tasks are executed.
Think of it like a factory assembly line for your data. The DAG is the master production schedule: the complete blueprint that defines every step to turn raw, unstructured data into a refined, valuable product. It doesn’t do the work itself, but it orchestrates the entire operation.
The Operators are the specialized workstations on the line. Each one is designed for a specific type of task: one station stamps metal (BashOperator), another applies a coat of paint (PythonOperator), and a third installs the wiring (PostgresOperator).
The tasks are the specific units of work performed at those stations. “Stamp door panel A” and “Stamp door panel B” might be two separate tasks using the same stamping workstation (Operator).
The dependencies are the conveyor belts that connect the workstations. They ensure that a chassis moves to the welding station before it arrives at the painting booth. This directed flow is what prevents a half-assembled product from moving forward.
Finally, the Airflow Scheduler is the plant manager. It’s responsible for ensuring the entire line runs on time, managing resources, and restarting any workstation that experiences a temporary failure.
Understanding Core DAG Components
Now, let’s translate this factory blueprint into code. Every DAG you ever write will be built from these core pieces.
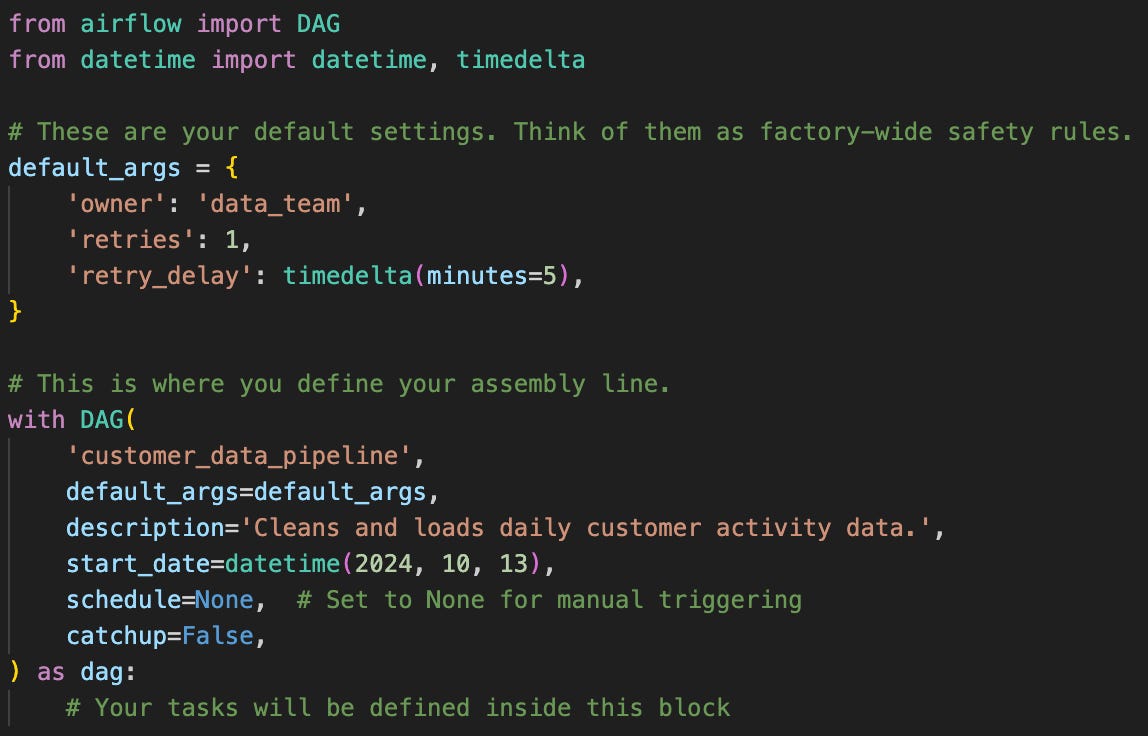
DAG Definition: Master Schedule
First, you define the DAG object. This is the container that holds your entire workflow. Here, you set the pipeline’s operational parameters: its name, how often production runs start (schedule), the start time of the first run, and the action to take if a task fails.
Operators as Specialized Workstations
Operators are the blueprints for your workstations. They define what kind of work a task will perform.
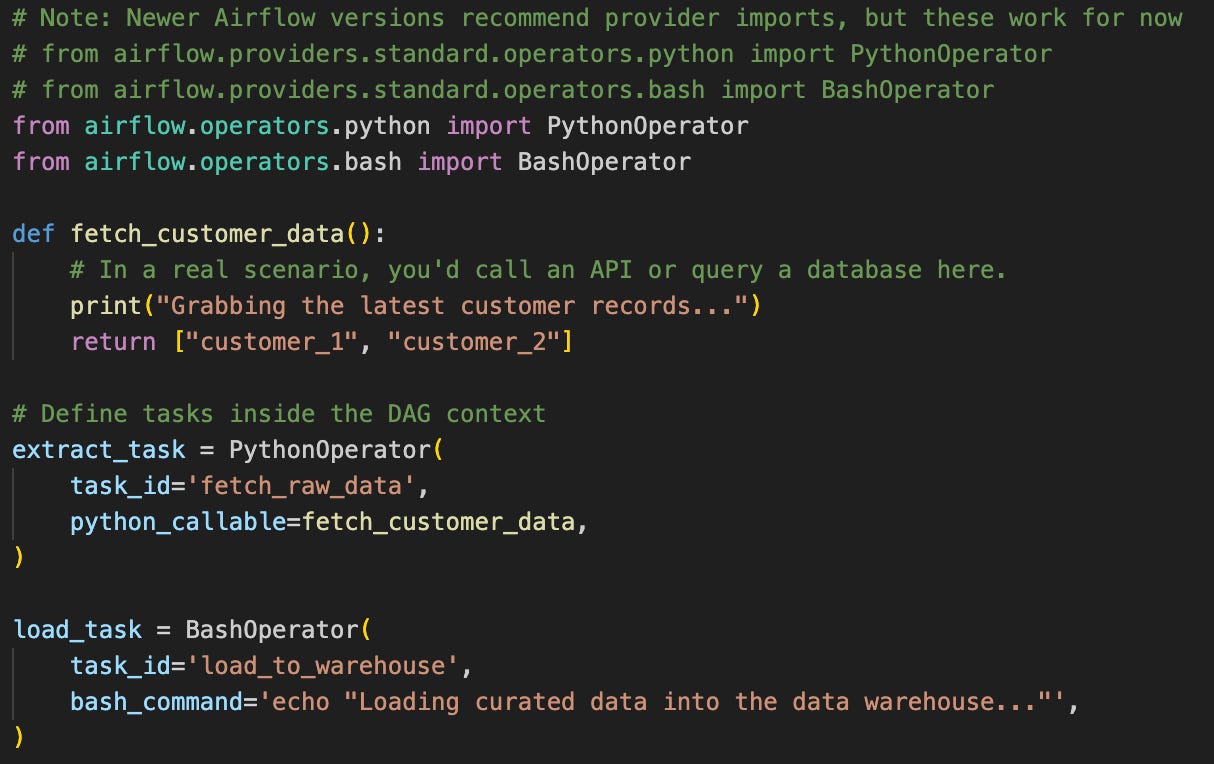
Tasks: Individual Work Orders
When you instantiate an Operator within a DAG, you create a Task. This is the specific work order that gets executed on the line.
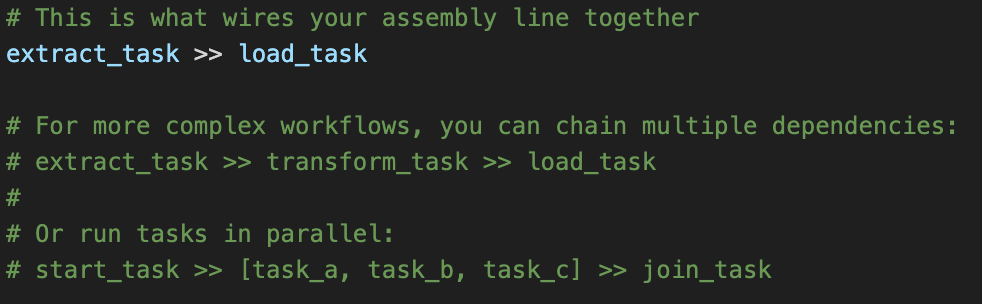
Task Dependencies: Conveyor Belts
This is where you connect your workstations and define the workflow.
From Beginner Concepts to Production Reality
Congratulations! You’ve just built your first Airflow DAG and grasped the core concepts. This is the essential foundation. Now, let’s talk about what happens when you take this foundation out of the tutorial and into the real world.
In production, the hardest problems are organizational. That straightforward task_a >> task_b >> task_c logic holds up in a controlled environment, but it crumbles when you’re dealing with:
API rate limits that change without warning
Data quality issues that surface at 2 AM
Four engineers from different teams all needing to modify the same DAG
Dependencies that look less like a straight line and more like a tangled web
This is where simple DAG construction meets the complex reality of data engineering. The basics we covered today are your foundation. The professional challenge is building DAGs resilient enough for your team, your data, and your production environment.
Now that you’re comfortable with the mechanics, the next question becomes: what patterns actually work when your pipeline needs to be not just functional, but resilient, maintainable, and scalable?
On Wednesday, we’ll move beyond theory into the practical patterns that make this possible. We’ll explore how to structure DAGs for collaboration, handle failure gracefully, and design workflows that scale with your organization’s complexity, not just against it.
For today, take these basics and stress test them. Hook a DAG up to a real data source and watch what breaks. That firsthand experience with the gaps between tutorial and production is the best preparation for what we’ll cover next.
The complete, runnable code for this DAG is available on The Data Letter GitHub. Feel free to clone it and experiment.
Happy orchestrating!
Hodman Murad
Fortunate to catch up on DAG as the first step in building a data pipeline, Hodman.