
Choosing Between Fine-Tuning, RAG, and Prompt Engineering: A $10K Decision Guide
Three questions to ask before building your LLM solution

Before you spin up training runs or build retrieval pipelines, answer these three questions. Most teams can’t, which is why they end up with overengineered solutions that underperform simpler alternatives.
Choosing between prompt engineering, RAG, and fine-tuning means matching your requirements to the right level of investment. Get this wrong, and you’ll spend weeks building something you could’ve solved in an afternoon.
Let’s fix that.
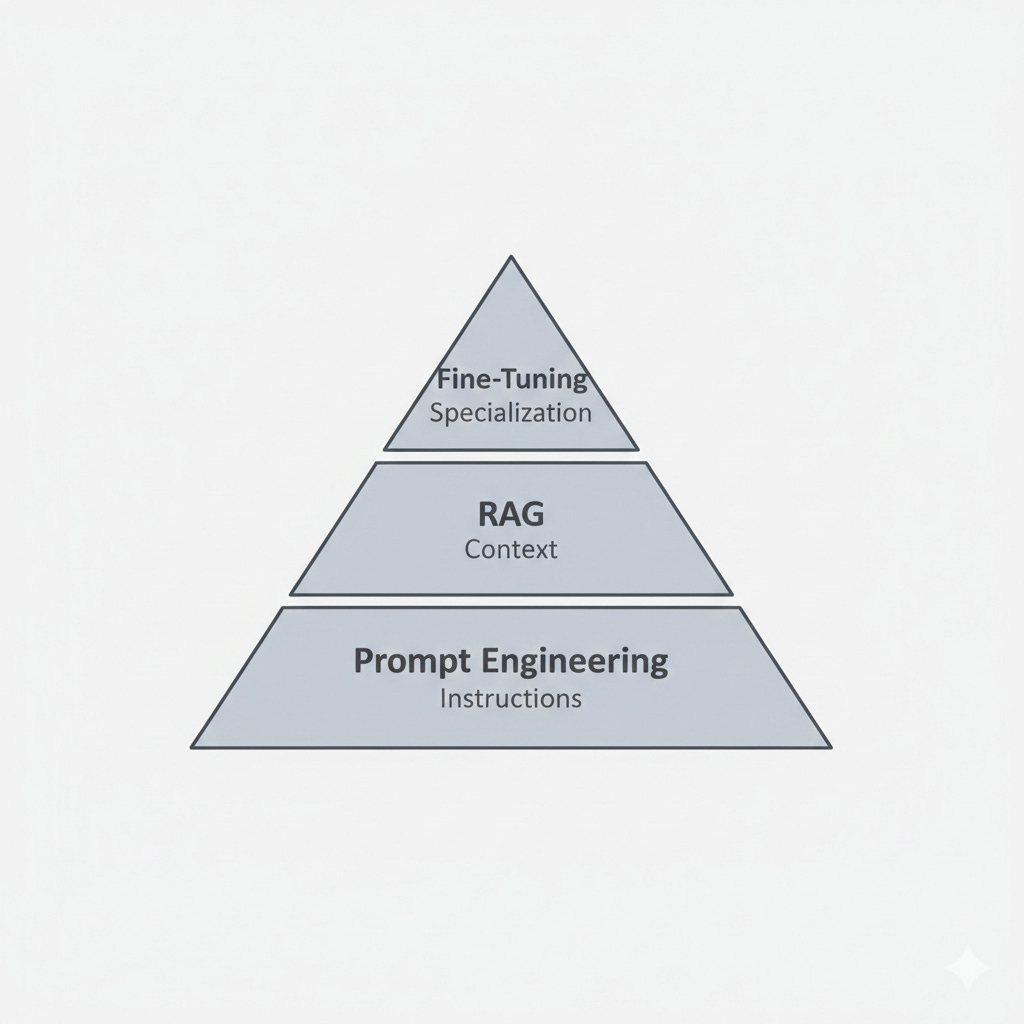
3-Layer Stack: What You’re Actually Choosing Between
Prompt engineering means crafting better instructions for a base model. You’re working entirely at the inference level, modifying inputs to get better outputs. The model stays the same, and you’re not pulling in external data.
RAG (Retrieval-Augmented Generation) adds a knowledge layer. You’re pulling relevant context from your documents or databases and injecting it into prompts at runtime. The model stays unchanged, but now it has access to your specific information.
Fine-tuning means retraining the model itself on your data. You’re modifying the model’s weights to specialize its behavior, teaching it patterns, formats, or domain knowledge that weren’t emphasized in the base training.
Three Questions That Determine Your Approach
Does the model already know how to do this task? If you’re asking GPT-5 to write marketing copy or summarize documents, the base capability exists, even if you need to refine the outputs through better prompts. Begin with prompt engineering to dial in the style and format. If you’re asking it to generate outputs in a proprietary format or follow domain-specific conventions it’s never seen, you might need fine-tuning.
Does the task require knowledge the model doesn’t have? When you need the LLM to reference your internal documentation, product specifications, or company policies, that’s a RAG problem. The model can reason about information, but it can’t memorize your entire knowledge base. Don’t fine-tune when you just need to feed in context.
Is consistent behavior across thousands of examples more important than flexibility? Fine-tuning shines when you need the model to reliably produce outputs in a specific style, follow particular reasoning patterns, or handle specialized scenarios that would require increasingly complex prompts. If you’re solving one-off tasks or experimenting with different approaches, the rigidity of a fine-tuned model works against you.
This week’s paid article:
Once you’ve answered these questions, consider the cost implications of each approach.
Cost Comparison at a Glance
Prompt engineering costs you time upfront, but keeps inference costs standard. You’re paying for the experimentation phase, not the deployment.
RAG adds infrastructure overhead. You need vector databases, embedding models, and retrieval logic. Your per-query cost increases because you’re making multiple API calls and processing additional tokens.
Fine-tuning flips the cost structure. High upfront investment in compute, data preparation, and evaluation. Lower per-query costs if you’re using a smaller model, higher costs if you’re fine-tuning large models and still using them at scale.
Use Case Examples
Here’s how these questions play out in real projects:
You’re building a customer support chatbot that needs to reference your FAQ documents and troubleshooting guides. That’s RAG. The model can already reason with the information you provide. RAG lets you surface the right documents at query time.
You’re generating SQL queries from natural language, and your database schema uses unconventional naming patterns that confuse base models. That’s a fine-tuning candidate. You want the model to internalize your specific patterns.
You’re summarizing meeting transcripts in a specific format with particular sections and bullet styles. Start with prompt engineering. Most models can follow formatting instructions if you’re clear enough. Only escalate to fine-tuning if prompt complexity becomes unmanageable.
You’re extracting structured data from unstructured medical notes, where the model needs to understand clinical abbreviations and context-dependent terminology. This might need fine-tuning if your domain vocabulary differs significantly from what’s in the training data.
‘Is This Overkill?’ Checklist
Before you commit to RAG or fine-tuning, run through these checks:
Can you solve this with 10 examples in your prompt instead of 10,000 examples in a training set? (If yes, you don’t need fine-tuning.)
Does your use case actually require real-time access to changing information? (If yes, RAG. (If no, maybe just better prompts.)
Will you be running this model hundreds of thousands of times? (If no, the cost optimization from fine-tuning probably doesn’t matter.)
Do you have clean, representative training data that teaches the model something it doesn’t know? (If no, don’t fine-tune.)
Can you describe your desired behavior in words? (If yes, try prompt engineering first.)
Bottom Line
Most teams skip straight to the expensive solution because it feels more sophisticated. But prompt engineering handles more use cases than people expect, RAG solves the knowledge problem without model changes, and fine-tuning should be your last resort, not your first instinct.
Start simple, escalate when you have evidence that simpler approaches won’t work.
This Wednesday, for paid subscribers, I’m sharing a complete fine-tuning guide, including dataset preparation templates, a conceptual LoRA walkthrough, platform research comparisons, and a cost-tracking spreadsheet you can adapt for your own projects.