
Year in Review: Top 3 Data Failures of 2025
Beyond the Obvious

The code examples used to fix these failures are available on The Data Letter's GitHub page. Follow along here as we walk through each solution.
If you’re reading this, you’ve likely debugged at least one production incident this year in which your monitoring looked fine until suddenly it didn’t. You’re in good company.
This year revealed something important: the era of simple, isolated data failures is behind us. We’ve gotten pretty good at handling model drift alerts and recovering from infrastructure crashes. Our monitoring catches those. Our runbooks handle them. Our postmortems document them.
But 2025’s most impactful failures weren’t the loud, obvious ones. They were insidious problems that crept through multiple layers of our increasingly complex data systems. Distribution shifts invalidated months of model training. Cross-modal contamination corrupted entire pipelines. Architectural assumptions collapsed under real-world load patterns.
These failures share a common thread: they emerged at the boundaries between systems, in the assumptions we encoded into our data contracts, and in the gaps between what we thought we were monitoring and what actually mattered. The failures emerged at the points where different systems connected, in the assumptions we encoded into our data contracts, and in the gaps between what we monitored and what actually mattered.
I was lucky enough to spend this year working on different freelance contracts with teams navigating exactly these kinds of failures. Let’s examine three technical failures that stood out this year, understand what really went wrong, and, more importantly, learn what we can do to prevent similar issues in 2026.
👋🏿 Hi, I’m Hodman, and I help companies build reliable data infrastructure. Here are some past articles you may have missed:
Failure #1: Training Data Distribution Shift
What Happened
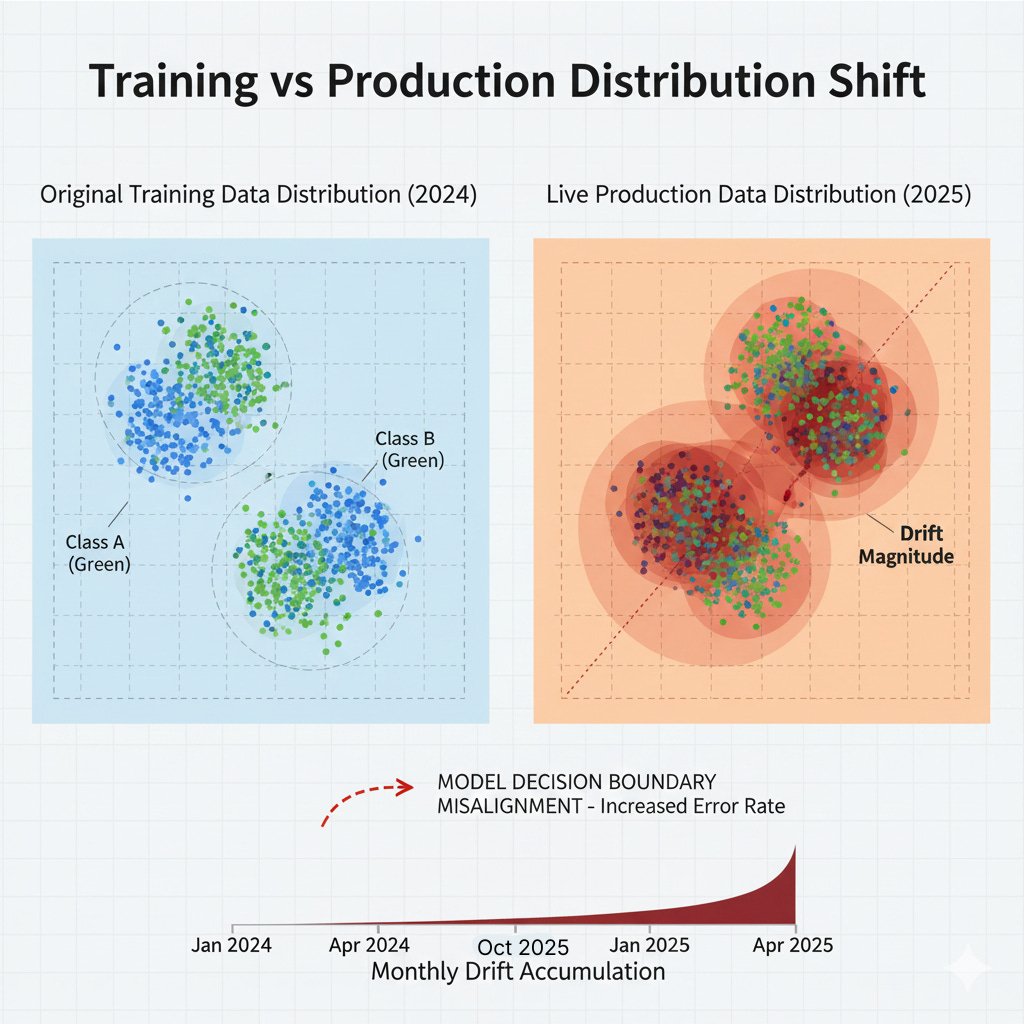
In early 2025, an e-commerce platform’s image recognition system began degrading. The model’s reported accuracy metrics remained stable at 94%, well within acceptable bounds. Customer support tickets, however, told a different story: users were reporting wildly incorrect product categorizations, particularly for fashion items and home goods.
The distribution of training data had shifted in ways that traditional monitoring systems couldn’t detect. The model was doing exactly what it was trained to do. The problem was that the world had changed.
Root Cause Analysis
The failure had three interconnected causes:
1. Metadata-Based Drift Detection Fell Short
The team’s monitoring focused on statistical properties like mean pixel intensity, color histograms, and image dimensions. These metrics remained stable because the image format didn’t change, but the content did. User photography trends shifted dramatically: increased use of AR filters, changing lighting preferences, and new smartphone camera features altered the visual characteristics of submitted images in ways that simple statistical measures couldn’t capture.
2. Temporal Dataset Staleness
The model was trained on a curated dataset from Q2-Q3 2024. By Q1 2025, visual trends had evolved enough that the learned feature representations no longer aligned with current image characteristics. The model had never seen images processed through newer smartphone AI enhancement features, which had become ubiquitous.
3. Proxy Metric Misalignment
Validation accuracy was measured on a holdout set from the same 2024 distribution. The model continued to hit its accuracy targets on this test set while failing in production. The team was optimizing for the wrong distribution.
Business Impact
Revenue Loss: 12% drop in conversion rates for affected product categories over six weeks
Support Costs: 3x increase in customer service tickets related to search and categorization
Trust Erosion: Measurable decline in repeat user engagement
Recovery Time: Four weeks to diagnose, retrain, and deploy a corrected model
⚠️ Key Lesson: Traditional statistical drift detection captures format changes but misses semantic shifts. Your model can be wrong while your metrics look fine.
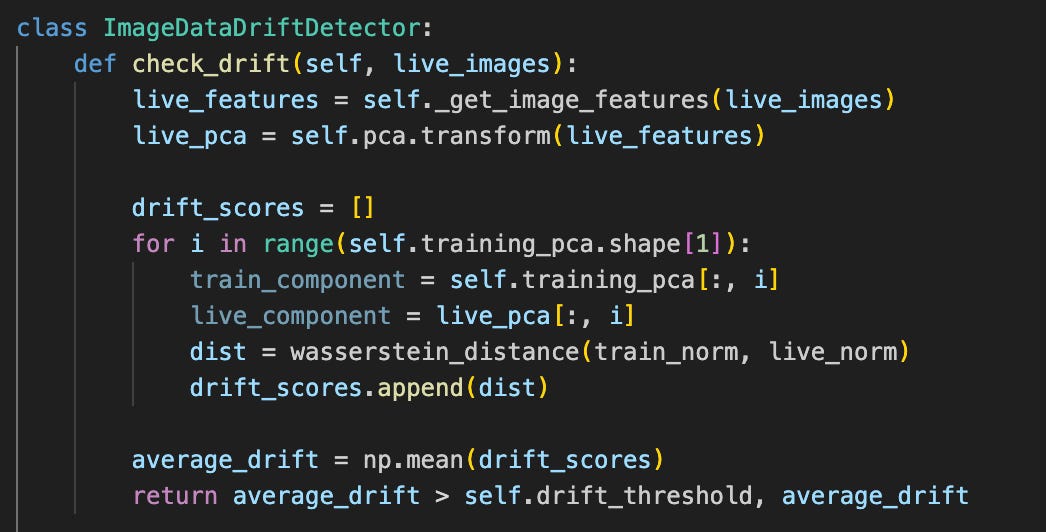
Embedding-Based Distribution Monitoring
We implemented a two-pronged approach that changed how their team thought about distribution monitoring:
This approach works by:
Semantic Feature Extraction: Using a pre-trained vision transformer to extract high-dimensional embeddings that capture semantic content rather than just pixel statistics
Distribution Comparison: Computing Wasserstein distance (also known as Earth Mover’s Distance) between reference and production embedding distributions
Adaptive Thresholding: Tracking drift velocity and triggering alerts when the rate of change exceeds baseline patterns
The approach works by comparing semantic embeddings rather than surface statistics. This allows the system to detect when production images represent fundamentally different visual concepts than training images, even when color histograms remain similar. By comparing semantic embeddings rather than surface statistics, the system could detect when production images represented different visual concepts than training images, even when color histograms remained similar.
Additional Safeguards Implemented:
Rolling Window Retraining: Automated weekly retraining with weighted sampling that emphasized recent data (70% from last 30 days, 30% from historical baseline)
Production Cohort Validation: Holding out random 5% samples of production data for real world validation before full model deployment
Semantic Drift Dashboards: Real-time visualization of cluster centroids in embedding space, making distribution shifts visible to the team
🌟 Level Up: Access the Complete 4-Part Framework
You’ve started on the path to stability by analyzing distribution shift. But what about the rest of the systems that keep your data platform reliable, compliant, and cost-efficient?
If you want the actionable blueprints to deploy these systems, rather than building them from scratch, you can get instant access to the full $146 toolkit by upgrading your subscription for just $5/month.
✅ The Pipeline Reliability Framework ($49 value)
✅ The Cloud Cost Optimization Framework ($49 value)
✅ The PII Scanner + Compliance Guide ($29 value)
✅ NEW! Pre-Holiday Freeze Runbook: Ship Confidently, Rest Easy ($19 value)
➡️ Get All 4 Frameworks FREE:
The problem of fragile contracts and invisible dependencies wasn’t confined to a single domain this year. Next, let’s examine how shared architectural assumptions broke a complex multimodal pipeline.
Failure #2: Multimodal Data Pipeline Contamination
What Happened
In March 2025, a customer service AI platform that processed both text and images started producing unusable suggested responses for support agents. Words appeared in the wrong order, sentences made no sense, and tokens appeared that didn’t match the input. Meanwhile, the image analysis component continued working normally.
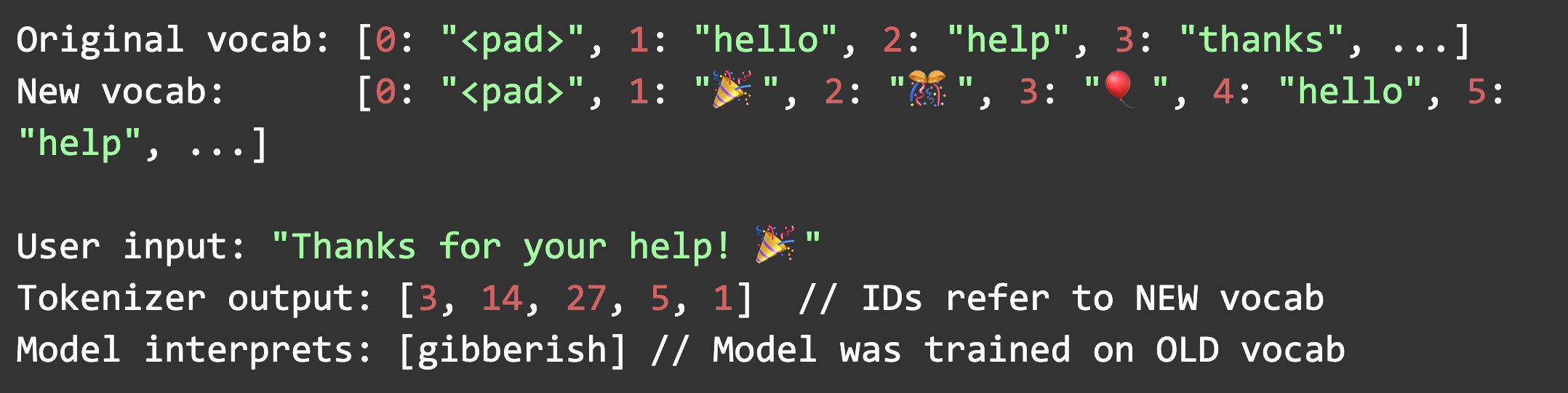
After digging in, the team discovered that emoji handling in the text preprocessing pipeline was corrupting the shared vocabulary used across multiple models. A minor change to support new Unicode emoji standards had cascading effects that took weeks to fully understand.
Root Cause Analysis
This failure stemmed from the tight coupling of the multimodal pipeline.
1. Shared Vocabulary Assumption
The platform used a unified tokenizer vocabulary shared between the text-only customer support model and the multimodal vision language model. On the surface, using a unified tokenizer made sense: one vocabulary to maintain, consistent token IDs across models. The downside was an invisible coupling between systems.
2. Silent Vocabulary Expansion
A routine update to support Unicode 15.0 emoji added 3,664 new tokens to the tokenizer vocabulary. The text preprocessing pipeline automatically incorporated these tokens, but the models were never retrained. Critically, no validation checks existed to verify vocabulary consistency between the tokenizer and the model weights.
3. Token ID Collision and Shift
New emoji tokens were added to the vocabulary in alphabetical order. This changed the indices of thousands of existing tokens. The models, trained with the old vocabulary mapping, now received token IDs that pointed to completely different words. When users included emojis in their messages (which are increasingly common in customer communications), the tokenizer would map them to IDs that the model treated as unrelated words or punctuation.
The cascade looked like this:
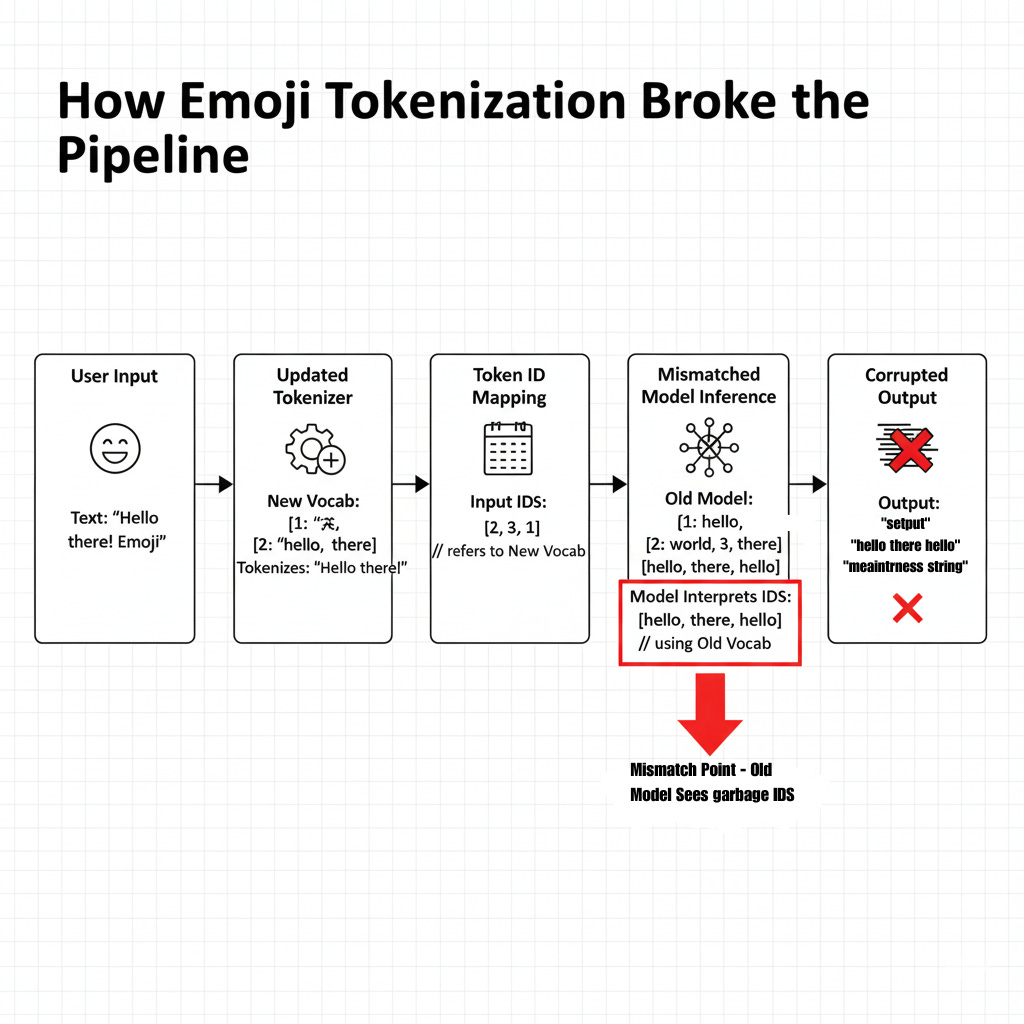
Business Impact
Service Degradation: 67% of conversations involving emojis produced incorrect AI suggestions
Agent Productivity: Average handling time increased 34% as agents ignored AI assistance
Emergency Response: Full rollback required, followed by three-week remediation
Technical Debt: Discovery of 14 other potential vocabulary mismatches across the pipeline
⚠️ Key Lesson: Shared resources in multimodal pipelines create invisible dependencies. Changes that seem isolated can have system-wide effects.
Vocabulary Contract Validation
The fix required both immediate remediation and systemic process changes:
Immediate Response:
Vocabulary Rollback: Reverted tokenizer to the pre-update vocabulary
Input Sanitization: Added emoji stripping as a temporary measure while models were updated
Emergency Retraining: Retrained all affected models with the new vocabulary
Long-term Architectural Changes:
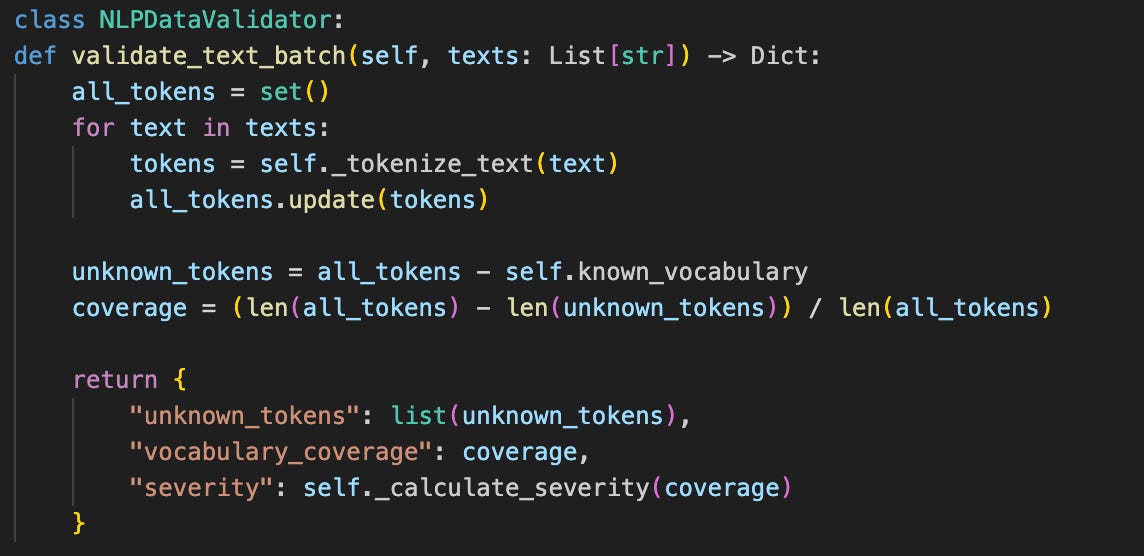
The validator prevents token ID shifts by catching unknown tokens before they can corrupt the model’s understanding, ensuring vocabulary consistency across deployments.
This validation system:
Freezes Vocabulary Snapshots: Creates immutable vocabulary checkpoints tied to specific model versions
Pre-Deployment Validation: Requires explicit vocabulary compatibility checks before any model or tokenizer deployment
Runtime Verification: Validates vocabulary consistency on model initialization, failing fast if mismatches are detected
Change Detection: Generates vocabulary diff reports highlighting any additions, removals, or index shifts
Additional Pipeline Safeguards:
Vocabulary Versioning: Implemented semantic versioning for tokenizer vocabularies (e.g.,
vocab-v2.1.0) with strict compatibility rulesContract Testing: Added integration tests that verify end-to-end token flow from input through all models
Staging Environment Parity: Required full multimodal pipeline validation in staging before production deployment
Monitoring Dashboard: Real-time tracking of out-of-vocabulary (OOV) token rates, with alerts on sudden increases
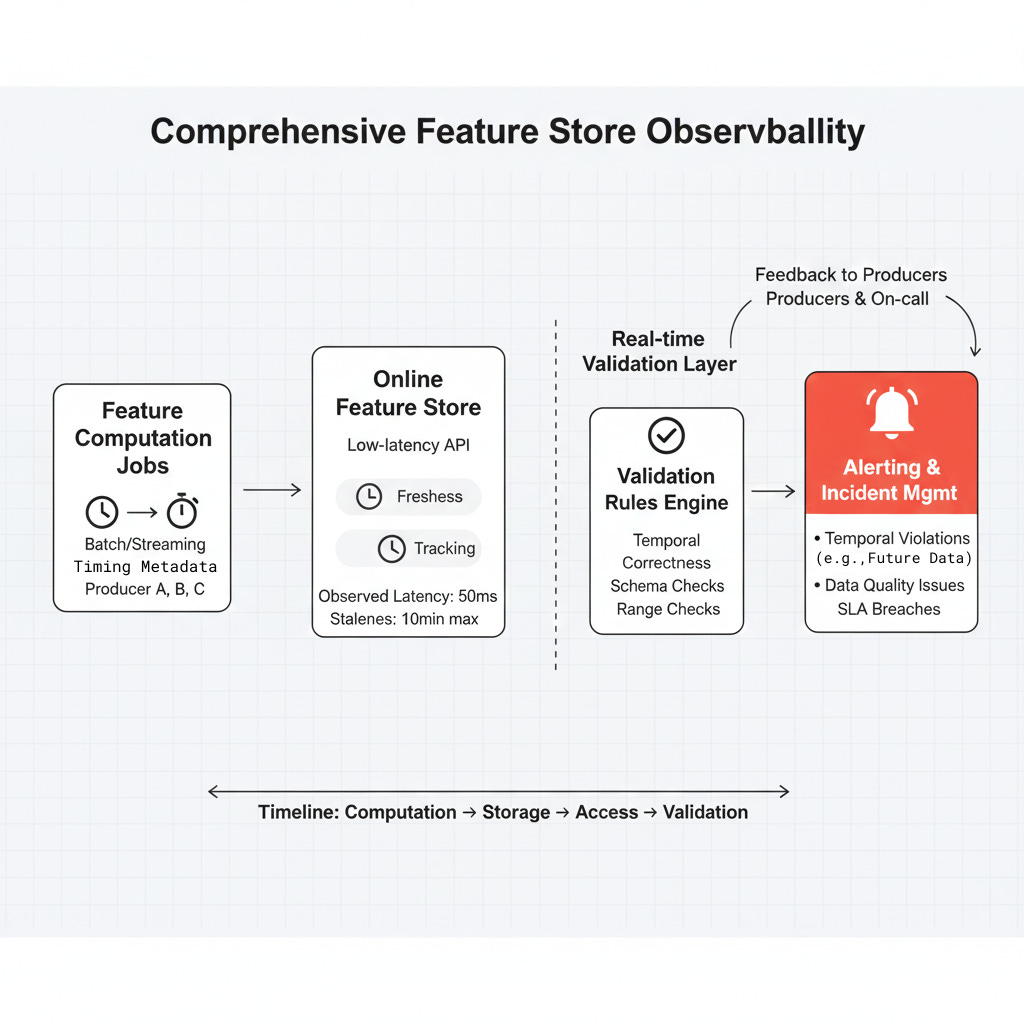
Failure #3: Real-Time Feature Store Backfill Blunder
The Problem
A fraud detection system at a fintech company experienced an incident that resulted in both false positives (legitimate transactions blocked) and false negatives (fraudulent transactions approved).
A well-intentioned infrastructure optimization that mixed online and offline feature serving in ways the system was never designed to handle. It was an architectural failure hiding behind an operational improvement.
Root Cause Analysis
The incident stemmed from a misunderstanding of feature store semantics:
1. Infrastructure Optimization Gone Wrong
The infrastructure team noticed that the offline feature store (used for batch model training and backtesting) and the online feature store (used for real-time inference) were largely redundant. Maintaining two separate systems seemed wasteful. They initiated a “backfill operation” to populate the online store with historical features from the offline store, enabling “warm-up” for new features and faster experimentation.
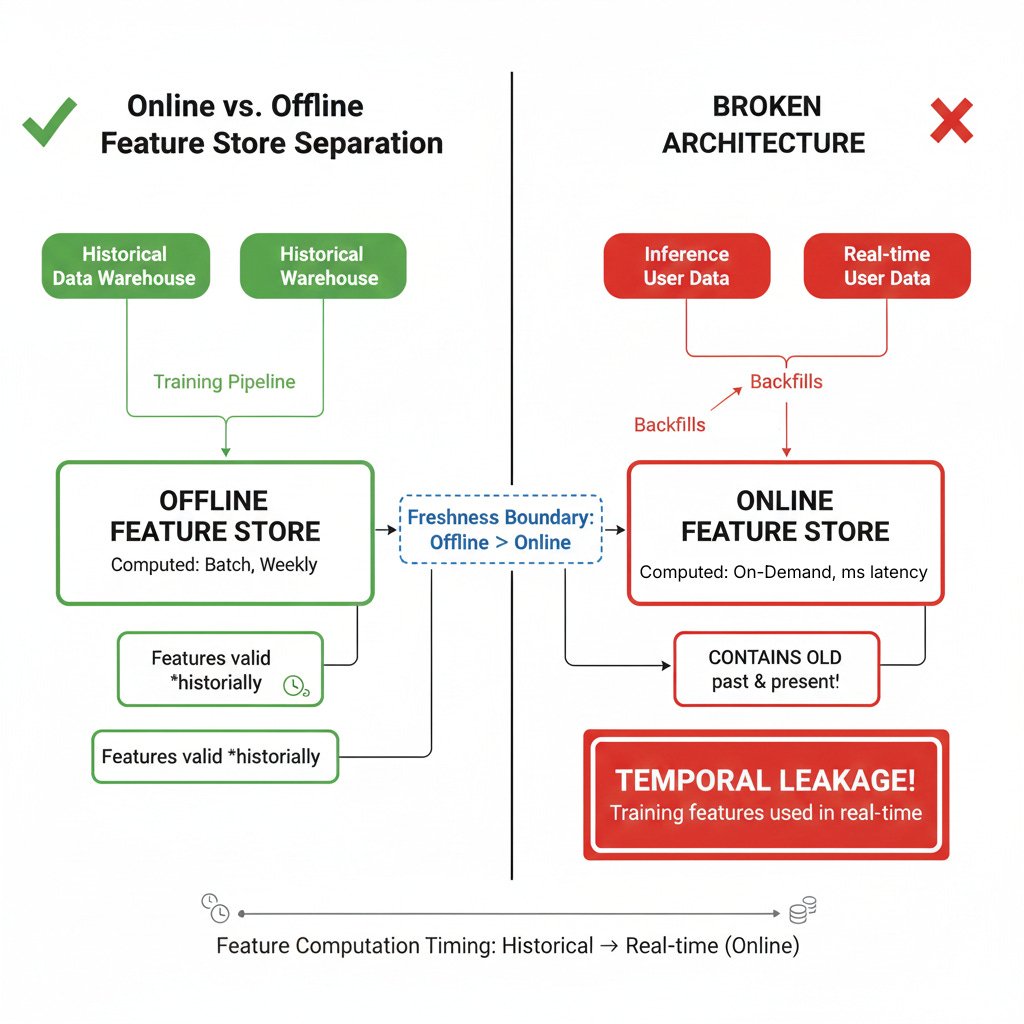
2. Temporal Semantics Violation
Here’s what they missed: offline features are computed with complete hindsight, incorporating information from the entire time window, including future data points relative to the prediction time. Online features, by necessity, can only use information available at inference time.
Example scenario:

When the backfill loaded offline features into the online store, it populated the feature store with values that contained future information. The fraud model began receiving features that were impossible to know at inference time.
3. How It Cascaded Through the System
The model had been trained to heavily weight certain temporal features that, in training, contained subtle future leakage. This leakage was acceptable (though not ideal) in the offline context because it was consistent. But when those same feature definitions were deployed to the online store with backfilled historical values, the model started making predictions based on data it shouldn’t have access to in production.
When the backfilled data ran out, and the system switched to truly real-time features, the model’s behavior changed dramatically. Fraud scores shifted systematically, triggering both types of errors.
Business Impact
Customer Impact: 240,000 legitimate transactions blocked, 1,400+ fraudulent transactions approved
Financial Loss: $870K in direct fraud losses, plus regulatory review costs
Operational Costs: 14-hour incident response involving 30+ engineers
Trust Impact: Customer complaints increased 18% among affected users
Regulatory Scrutiny: Extended audit of ML risk management practices
⚠️ Key Lesson: Feature stores aren’t just databases. The temporal semantics of features are part of the contract, and violating them breaks the model’s assumptions.
Feature Store Client with Temporal Safety
The remediation involved both immediate fixes and architectural redesign:
Immediate Response:
Rollback: Purged contaminated online feature store and rebuilt from real-time sources
Feature Audit: Reviewed all 284 features for potential temporal leakage
Model Revalidation: Retrained and revalidated models with strictly time-respecting features
Long-term Architectural Changes:
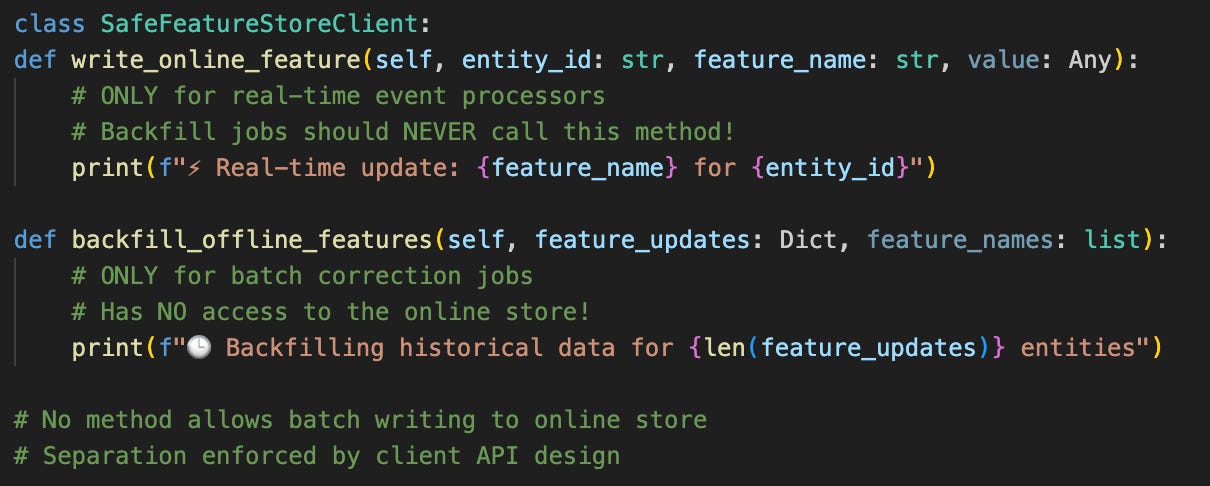
The SafeFeatureStoreClient enforces this temporal separation by architecturally preventing batch writes to the online store, making temporal contract violations impossible.
This client enforces several critical invariants:
Temporal Mode Enforcement: Features are explicitly tagged as
offlineoronline, with compile-time checks preventing cross-contaminationPoint-in-Time Correctness: Online feature requests include a
timestampparameter, and the client verifies that the requested features only use data available before that timestampFeature Definition Versioning: Each feature has a version hash based on its computation logic, preventing accidental mixing of incompatible feature versions
Fallback Handling: Explicit handling of missing features rather than silent backfills
Additional Safeguards:
Feature Freshness Monitoring: Real-time tracking of feature age, with alerts if online features exceed expected staleness thresholds
Deployment Gates: Required proof that all features used in a model deployment exist and are correctly configured in the target feature store
Shadow Mode Testing: New feature store clients run in shadow mode for 72 hours, comparing results against the production client before cutover
Temporal Audit Logs: Complete lineage tracking showing when each feature value was computed and what data it used
Common Thread: Brittle Data Contracts
Looking across these three failures, a pattern emerges. Each incident involved a breakdown in the implicit contracts between system components:
Distribution Contracts
The image recognition failure occurred because there was no formal contract specifying the distribution of images for which the model was valid. The team implicitly assumed “images will always look like our training data,” but had no mechanism to verify or enforce this assumption.
Vocabulary Contracts
The multimodal pipeline contamination occurred because models and tokenizers lacked an explicit contract regarding vocabulary consistency. The system allowed changes that violated model assumptions without any validation.
Temporal Contracts
The feature store backfill disaster stemmed from violating the temporal contract between training and inference. Features computed with future knowledge were served at inference time, breaking the model’s causal assumptions.
💡 Key Insight: Data contracts encode assumptions about distributions, semantics, temporal validity, and system boundaries. When these contracts are implicit rather than explicit, they break silently.
Lessons for 2026: Building Resilient Data Systems
As we move into 2026, here are actionable principles learned from this year’s failures:
1. Make Contracts Explicit and Testable
Don’t rely on assumptions encoded in comments or tribal knowledge. Write contracts as code:
Distribution contracts: Define expected statistical properties and semantic characteristics of data
Vocabulary contracts: Version and validate tokenizer-model compatibility
Temporal contracts: Explicitly tag features with their temporal semantics and enforce them
2. Monitor What Matters, Not What’s Easy
Traditional monitoring often tracks what’s easy to measure (accuracy on a fixed test set, mean pixel values) rather than what matters (alignment with current production distribution, semantic drift, temporal correctness). Invest in monitoring that captures the semantics of your system.
3. Validate Across Boundaries
The worst failures happen at integration points, between models and tokenizers, between offline and online systems, and between training and inference environments. Build validation layers at every boundary:
Pre-deployment integration tests
Runtime contract verification
Cross-system compatibility checks
4. Design for Temporal Correctness
Time is special in ML systems. Features, models, and data all have temporal validity ranges. Build systems that:
Design systems that make it impossible to accidentally use future data at inference time
Track when each feature was computed and what data it used
Validate that data flows through pipelines in the correct temporal order
5. Embrace Staging Parity
Many failures could have been caught in staging if staging environments truly mirrored production. This includes:
Running real production data through staging (with appropriate privacy controls)
Maintaining multimodal pipeline parity
Testing with production-scale data volumes
6. Build Rollback Capability Into Everything
Every system component should support instant rollback:
Model versions
Feature definitions
Tokenizer vocabularies
Infrastructure configurations
The ability to quickly revert bad changes is often more valuable than preventing them in the first place.
Failing Forward
What made these failures instructive was how they revealed the complexity of these systems and the assumptions that were built into them. Each incident was a reminder that as our ML systems grow more sophisticated, our approach to reliability and validation must evolve in parallel.
The teams that recovered fastest shared a few common traits, regardless of their model complexity or team size. They were the teams that had invested in:
Clear contracts between system components
Monitoring that captures semantic correctness, not just statistical properties
Validation layers at integration points
Rapid rollback capabilities
As you plan your 2026 roadmap, consider: Where are your implicit contracts? What assumptions are encoded in your systems but not validated? What boundaries lack proper integration tests?
Preventing failures is impossible in complex systems. What matters is failing safely, detecting failures quickly, and learning systematically. Make your data contracts explicit, validate them continuously, and build systems that fail gracefully when assumptions are violated.
Here’s to a more resilient 2026.
🛠️ Stop Building from Scratch: Own the Systems
This year’s failures revealed a definitive truth: building a stable, reliable data platform requires proven systems, not constant custom engineering.
You now understand the critical failures related to Distribution, Temporal, and Vocabulary contracts. Are you ready to move from understanding the problems to deploying the solutions?
Option 1: The Full Toolkit (Best Value) 🏆
Get instant, unlimited access to the complete $146 framework library, all future toolkits, and the paid article archive when you upgrade your subscription for just $5/month. This is the highest leverage solution for long-term reliability.
Option 2: Single Framework Purchase
If you only need to tackle one specific operational challenge right now, you can purchase any framework individually:
Don’t just learn from 2025’s failures. Equip yourself to prevent them in 2026.
Thanks Hodman for another excellent post. I definitely had more than a tingle of schadenfreude reading about these data failures, but it was also a useful reminder to not get too complacent. And of course to keep reading your substack to make sure I am following the most effective practices. 🙏
“Service Degradation: 67% of conversations involving emojis produced incorrect AI suggestions”
They are surprisingly good at prompt injection… too funny imho!